Debug Log #3: Stale reads caused by process pausing
March 1, 2026
今天分享的问题是 Stale reads caused by process pausing,它由 SIG-ETCD Leader Marek Siarkowicz 完成定位并修复。
问题介绍
社区每天都会运行 antithesis 的故障注入测试。整体流程是:先启动一个三节点的 etcd 集群,再启动多个客户端并发执行读写;在读写过程中,antithesis 平台会随机注入短暂故障。待客户端操作结束后,测试会对结果进行数据一致性校验,其中一项关键检查就是 Linearizability - 线性一致性。线性一致性校验方面,社区使用 porcupine 的可视化方法:客户端会记录每一次请求的返回结果,以及请求发出与响应返回的时序,呈现出来的效果如下。
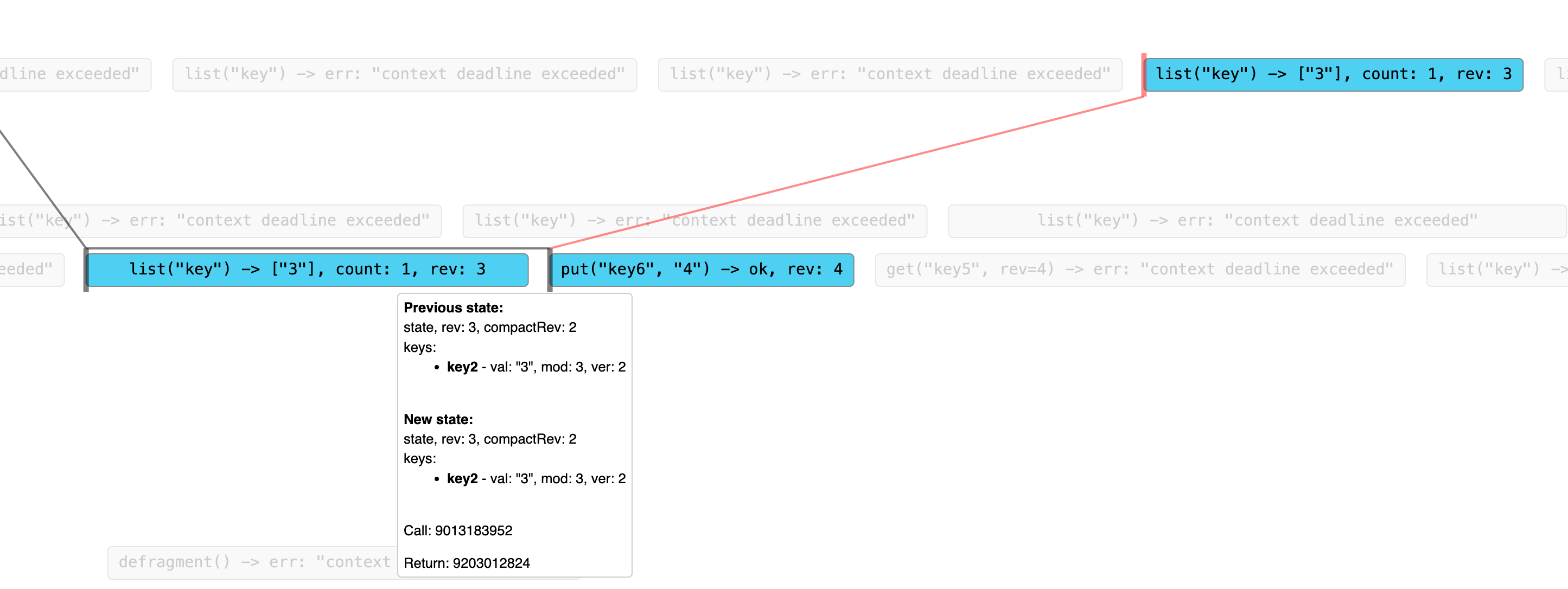
测试会随机暂停某个 etcd 成员进程 2-3 秒(例如通过 cgroup freeze,或对进程发送 SIGSTOP)。问题在于:当原 Leader 暂停恢复后、但尚未意识到已选出新 Leader 之前,它仍可继续处理线性一致性读请求。如上图所示,某客户端已经成功将值更新为 key6=4,并观察到集群的 Revision 为 4;但随后另一个客户端发起读请求时,却读到了 Revision 为 3 的旧数据。这就出现了数据不一致的问题。这种进程停顿在实际场景中还挺常见的,比如底层物理机出现问题需要迁移虚拟机,这种迁移可能会导致短暂的停顿。
ReadIndex
为了实现线性一致性的读操作,etcd 采用 ReadIndex 机制 ( Raft - 6.4 Processing read-only queries more efficiently ):当 Leader 收到线性一致读请求时,它不会直接用本地状态返回,而是先通过一次广播心跳来确认自己仍然是 Leader,从而避免在发生 Leader 变更或网络故障时读到过期数据。
Leader 发起一轮 ReadIndex 流程,向其他节点发送心跳(本质是空的 AppendEntries)。这些心跳会携带一个 Request-ID 作为上下文,用来标识这次 ReadIndex 请求。Follower 不需要解析这个上下文,只需按 Raft 协议正常响应心跳即可。Leader 收到多数派的确认后,就能确定一个安全的 readIndex(对应当时已经被多数派确认的提交进度)。
etcd Leader 在管理 ReadIndex 这件事时,思路其实很直接: 用 Request-ID 作为这次请求的唯一标识,然后按照请求进入流程的先后顺序排队,也就是入队 readIndexQueue。等收到 Follower 回来的心跳响应之后,如果心跳上下文里的 Request-ID 已经拿到了多数派确认,那有意思的地方就来了: etcd Leader 并不是「哪个请求确认了,就只处理哪个请求」。它 advance 函数会从队头开始扫描 readIndexQueue,一直处理到这个 Request-ID 为止。也就是说,一旦某个请求得到确认,那排在它前面的那些请求,它都会可以顺带确认了。
每个 etcd 成员都有一个名为 linearizableReadLoop 的守护协程,用来发起 ReadIndex 请求,从而确认当前最新、已达成共识的 CommitIndex。每次请求的超时大约是 7 秒。除非等待超时,或节点检测到 Leader 发生变化,否则它不会放弃这次请求,而是每隔 500 毫秒使用 同一个 request ID 继续重试。
迟到的双心跳反馈
假设三个成员分别是 etcd0、etcd1、etcd2,当前 Leader 是 etcd0(term=2)。
在停止 etcd0 进程之前,etcd1 收到来自 client1 的线性读请求,于是向 Leader etcd0 发送 ReadIndex(reqID=10)。同时,etcd0 对外发送心跳 Heartbeat(term=2, context=[reqID=10]),紧接着 etcd0 被暂停。
etcd1/etcd2 收到心跳后,分别返回 HeartbeatResp(term=2, context=[reqID=10])。但 etcd1 一直没有等到 etcd0 返回的 MsgReadIndexResp,因此它会继续重试:不断发送同一个 ReadIndex(reqID=10),直到它发现集群已经出现新 Leader etcd2(term=3)。
由于数据量不大、机器也没死,暂停期间内核仍在收包;再加上暂停时间并不长,etcd0 恢复后仍能收到暂停期间积压的消息:HeartbeatResp(term=2, context=[reqID=10], from=etcd1)、后续重试的 ReadIndex(reqID=10),以及 HeartbeatResp(term=2, context=[reqID=10], from=etcd2)。可以确定的是:etcd1 的重试 ReadIndex(reqID=10) 一定发生在它发送 HeartbeatResp(term=2, context=[reqID=10], from=etcd1) 之后;但 etcd0 恢复后,协程调度时间不确定,所以不确定 HeartbeatResp(term=2, context=[reqID=10], from=etcd2) 和 ReadIndex(reqID=10) 的顺序。
假设 etcd0 恢复后,又收到了 client2 一个直接发给它自己的线性读请求,那么它会产生新的 ReadIndex(reqID=20),并向其它两个成员发起新一轮心跳来等待多数派的确认。由于 etcd0 和其它成员之间的连接并没有断开,新一轮心跳的回包在「发生时间」上肯定晚于上一轮 term=2 的回包。如果此时 readIndexQueue 的顺序刚好变成 [reqID=20, reqID=10],那么当 etcd0 处理到 HeartbeatResp(term=2, context=[reqID=10], from=etcd2) 时,就可能错误地确认队头的 reqID=20。于是 client2 会直接在 etcd0 本地完成线性读;一旦新 Leader etcd2(term=3) 产生新的数据变化,那么 client2 就会读到旧 Revision,从而形成 stale read。
| 时间 | 发送方 → 接收方 | 消息 / 动作 | Term | 备注 |
|---|---|---|---|---|
| T0 | — | etcd0 是 Leader | 2 | 初始状态 |
| T1 | client1 → etcd1 | 线性读触发 | 2 | |
| T2 | etcd1 → etcd0 | ReadIndex(reqID=10) | 2 | |
| T3 | etcd0 → etcd1/etcd2 | Heartbeat(context=[reqID=10]) | 2 | |
| T4 | — | etcd0 被暂停 (SIGSTOP / freezer) | 2 | 用户态不处理消息,但内核仍在收包 |
| T5 | etcd1/etcd2 → etcd0 | HeartbeatResp(context=[reqID=10]) | 2 | |
| T6 | etcd1 → etcd0 | ReadIndex(reqID=10) | 2 | 重试 |
| T7 | etcd2 成为新 Leader | Leader 切换 | 3 | |
| T8 | — | etcd0 恢复 | 2/3 | |
| T9 | client2 → etcd0 | 线性读触发 | 2/3 | |
| T10 | etcd0 → etcd1/etcd2 | Heartbeat(context=[reqID=20]) | 2/3 | 为 reqID=20 等待多数派确认 |
| T11 | etcd0 | 处理 Heartbeat(context=[reqID=10],from=etcd1) | 2/3 | |
| T12 | etcd0 | 处理重复的 ReadIndex(reqID=10,from=etcd1) | 2/3 | |
| T13 | etcd0 | 处理迟到的 Heartbeat(context=[reqID=10],from=etcd2) | 2/3 | 确认 T10 - ReadIndex(reqID=20) 的请求 |
| T14 | etcd0 | client2 读本地状态机 | 2/3 | 若 etcd2(term3) 有新的数据变化 → stale read |
解决的方案就是避免在 linearizableReadLoop 守护协程里使用重复的 Request-ID。
最后
为了避免先入为主,在查看修复代码之前,我会先过一遍测试日志和关键路径源码,先把可能原因收敛到一个大致范围,再回头对照修复方案。
这次排查给我带来灵感的是十年前的一条审阅评论——raft: support safe readonly request。虽然和这次问题不算直接相关,但这确实是调试的乐趣。
最后我在本地用 SIGSTOP 跑了几个小时就把问题复现出来了。这次没有用 AI,不过后续可以整理一个 SKILL,用来更系统地分析这类测试日志。