Streaming JSON/Protobuf in Kubernetes
February 3, 2025
OOM-KILL
当 kube-apiserver 处理 LIST 请求时,它会一次性将数据序列化为 JSON 或 Protobuf 格式,然后交由底层的 Go/http 处理。根据标准的 encoding/json 库实现,kube-apiserver 需要分配一大块内存来存放完整的序列化结果。更严重的是,这块内存要等到数据的最后一个字节被传输完毕后才会释放,容易导致高峰时的内存占用激增。
在 Go/http2 实现中,每个 http2/stream 都有一个传输队列,队列中的成员存储需要发送的数据。多个 http2/stream 共享同一个 TCP 连接,为了保证公平性,Go 按顺序选择 http2/stream 并限制每次发送的数据量。由于每个 http2/stream 只有有限的发送窗口,数据会像“挤牙膏”一样逐步推送。然而,在 kube-apiserver 的实现中,每个 http2/stream 的传输队列通常只有一个成员指向序列化的数据,该成员会一直持有完整的序列化数据,直到传输完毕才释放。如果短时间内有多个大请求,kube-apiserver 会迅速消耗大量内存,甚至可能导致 OOM 崩溃。
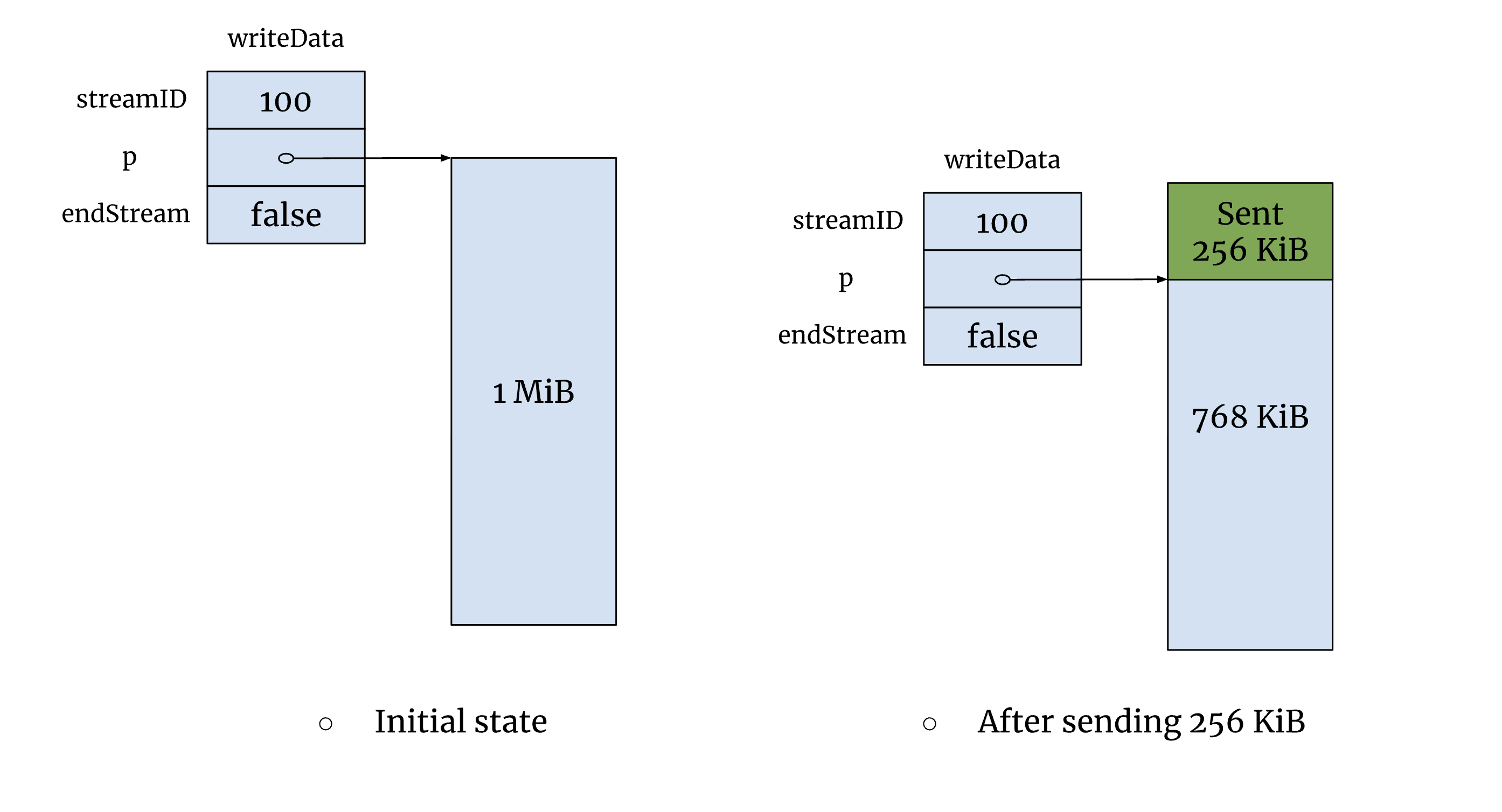
更揪心的是 encoding/json 的实现。虽然它内部使用了 sync.Pool 来提高内存复用率,但这也带来了一个隐患:如果先处理了少量的大请求,而后续主要是大量的小请求,那么 sync.Pool 可能会长期持有之前分配的大块内存,而这些内存无法及时释放。在这种情况下,kube-apiserver 的内存占用无法真实反映当前的请求负载,即使大请求已经结束,进程仍可能维持较高的内存使用率。– Kubernetes#114276
KEP-5116
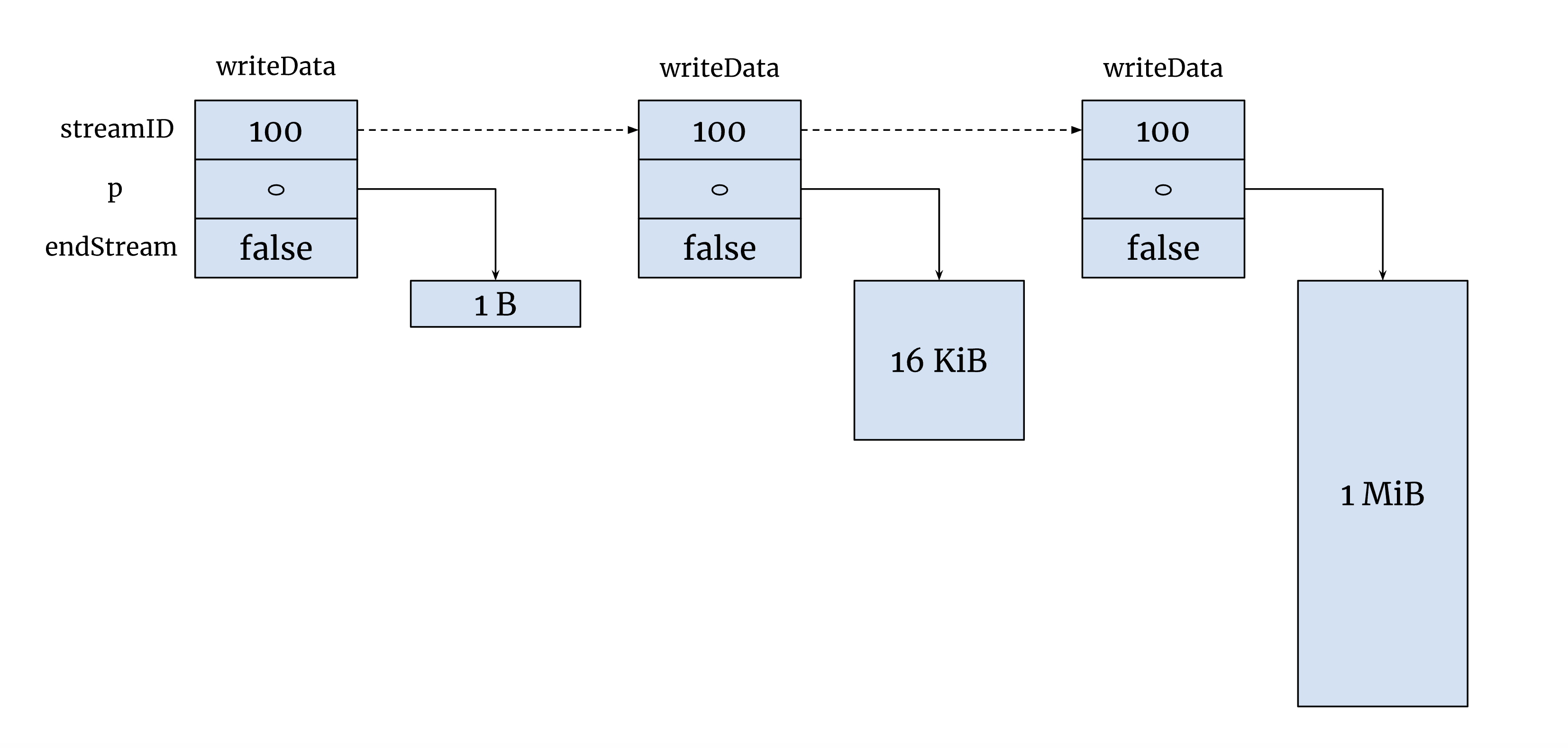
解决这个问题的关键在于引入 流式处理 来序列化数据。KEP-5116 根据 LIST 响应的结构特点,可以依次序列化 TypeMeta、ListMeta,然后逐项序列化 Items,避免一次性分配和持有大块内存,从而降低内存占用。
type XYZList struct {
metav1.TypeMeta `json:",inline"`
// Standard list metadata.
// More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds
// +optional
metav1.ListMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"`
// List of XYZ.
// More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md
Items []XYZ `json:"items" protobuf:"bytes,2,rep,name=items"`
}
这样不仅解决了 encoding/json 大内存回收的问题,还解决了 Go/http2 的内存管理问题。 在流式处理的模式下,http2 stream 的队列成员数量会增加,但每个成员最多只会引用 1-2 MiB 的内存,并在发送完毕后及时释放。 此外,根据 Go/http2 的实现,当网络较为繁忙时,kube-apiserver 无法无限制地向 http2/stream 队列中添加待发送的数据成员,从而在一定程度上抑制了内存的过快增长,进一步提升了系统的稳定性。
Benchmark
实验准备:
- 1024 个 configmap,每个 configmap 大小为 1 MiB
- 每个请求数据量为 100 MiB, 数据格式为 JSON,请求不经过 ETCD
- 每秒最多发出 10 个请求,客户端最多并发处理 100 个请求
- 一共发出 6000 个请求
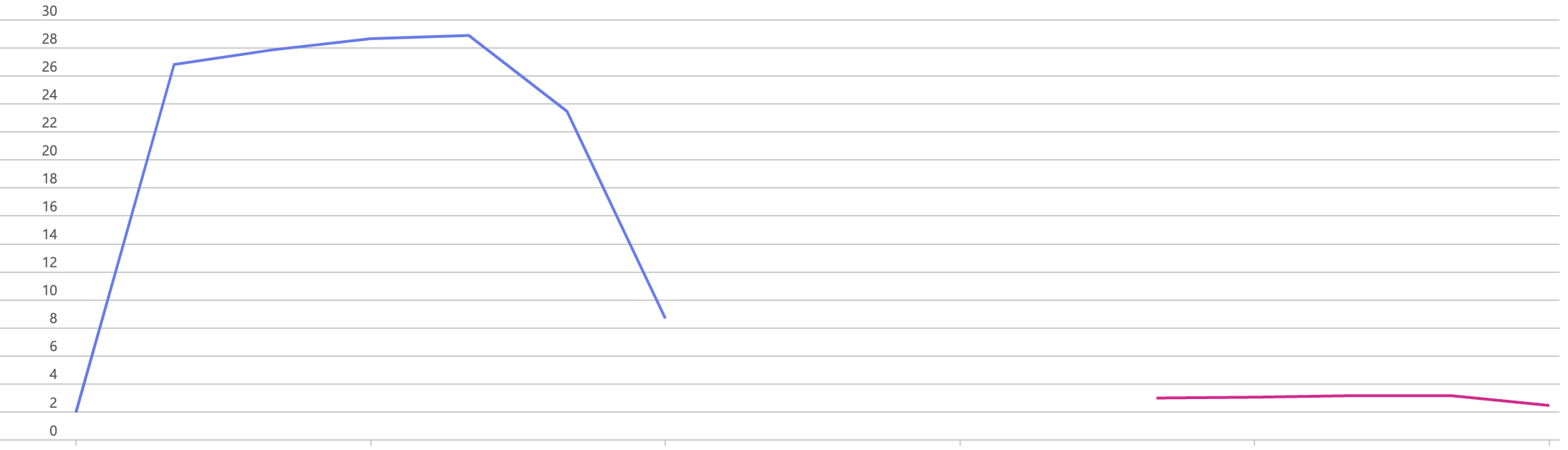
下图左侧的为 kube-apiserver v1.32.0 版本,它最高消耗了将近 29 GiB; 而采用了 Kubernetes#129334 的版本仅仅需要 2-3 GiB,内存占用大幅降低。 这个优化方案比 WatchList 实用性更强,客户端不需要做任何改造。可惜这么好的优化,上游不愿意 backport 到老版本上。
65K Nodes?
Kubernetes 在近几个版本的优化都挺给力的,比如 v1.31 ConsistentListFromCache 可以很大程度避免击穿背后的 ETCD,再配合上基于缓存的分页能力,ETCD 仅需要做好数据推送的任务就好了。最后再配合上 KEP-5116,65K 节点不是梦啊 :)
NOTE: 这个问题同样存在于 gRPC-go 的 UnaryCall 方式中。除非服务端一开始就采用 gRPC-go StreamCall 进行流式传输,否则在处理大规模数据时,仍然可能触发 OOM-KILL。ETCD 也面临类似的挑战,但 Kubernetes 目前的优化策略更倾向于让 ETCD 专注于数据推送,而由 kube-apiserver 承担数据处理的压力。从这个角度来看,Kubernetes 也算是间接解决了这个问题。