Debug Log #2: Using AI to Fix a Flaky Containerd ENXIO Test Case
November 25, 2025
ENXIO: no such device or address
在 containerd v2.2 发布前期,我们多次遇到与 loop(4) 块设备相关的测试用例 TestLoopbackMount 出现不稳定的问题,但在本地环境却始终无法复现。我在审阅代码时碰到这种失败的频率并不高,重试一下通常就能通过,所以当时并没有太在意。直到最近我连续点了好几次重试之后,我真的不想再当 S(oftware) R(etry) E(ngineer) 了。
=== FAIL: core/mount/manager TestLoopbackMount (0.05s)
log_hook.go:47: time="2025-10-23T21:49:22.532811960Z" level=debug msg="activating mount" func="manager.(*mountManager).Activate" file="/home/runner/work/containerd/containerd/core/mount/manager/manager.go:134" mounts="[{loop /tmp/TestLoopbackMount989607109/001/fs-1621892597 []} {format/ext4 {{ mount 0 }} []}]" name=id1 testcase=TestLoopbackMount
helpers.go:100: unmount /tmp/TestLoopbackMount989607109/001/test-mount-3030342351
manager_linux_test.go:80:
Error Trace: /home/runner/work/containerd/containerd/core/mount/manager/manager_linux_test.go:80
/home/runner/work/containerd/containerd/core/mount/manager/manager_linux_test.go:105
Error: Received unexpected error:
failed to get loop device info: no such device or address
Test: TestLoopbackMount
TestLoopbackMount
在真实的生产环境里,基本不会有人用 loop 设备当存储后端。不过在测试环境就不一样了,总不能为了跑几条测试就给 CI runner 挂一块 NVMe 盘吧。containerd 在这里其实只负责 snapshot 的生命周期管理,真正的差异主要来自不同文件系统的实现。所以,用 loop 设备来跑测试已经足够覆盖这部分逻辑,也是最简单直接的方案。
containerd v2.2 将 loop 设备挂载抽象成 mount manager 的插件,挂载流程相对简单:
| 步骤 | 操作 | 说明 |
|---|---|---|
| 1 | ioctl(2) + LOOP_CTL_GET_FREE 获取 /dev/loopX |
找到一个可用的 loop 设备 |
| 2 | ioctl + LOOP_CONFIGURE(后端文件 + LO_FLAGS_AUTOCLEAR) |
绑定文件并设置自动清理标志 |
| 3 | 创建 /dev/loopX 的软链接 |
方便管理,重启后仍能通过软链接找到设备 |
| 4 | 取消 LO_FLAGS_AUTOCLEAR |
允许 containerd 重启或其他进程重新挂载该设备 |
| 5 | 挂载 | 将 loop 设备挂载到目标路径 |
| 6 | 取消挂载 | 卸载 loop 设备 |
| 7 | 打开 /dev/loopX 并重新设置 LO_FLAGS_AUTOCLEAR |
确保设备在关闭句柄后自动释放 |
| 8 | 关闭 /dev/loopX 句柄 |
完成释放流程 |
第 3、4 步主要用于简化管理,确保 containerd 重启后,loop 设备的后端文件不会被意外清空,同时通过软链接方便找到设备号。
即使多个进程同时通过 LOOP_CTL_GET_FREE 获取相同的可用设备号,内核在绑定后端文件时会加锁,确保只有一个进程成功绑定。其他进程会收到 EBUSY 错误,它们只需重新获取设备号即可。重试逻辑和现有的 losetup(8) 保持一致。
但是在第 7 步,TestLoopbackMount 出现了错误。当它尝试获取设备配置信息时,内核返回了 ENXIO。这个错误表示该设备没有绑定任何后端,因此无法获取状态。
在确认内核锁能够保证不会出现并发问题后,可以断定,错误原因是其他进程调用了 ioctl(LOOP_CLR_FD) 来清理了「错误」设备号。
Using AI?
最直接的方法就是启动一个 Vagrant Box,运行和 CI 环境一模一样的内核版本,然后不停地跑测试;同时写一个小的 eBPF 程序来监控所有的 ioctl 系统调用。只要能复现问题,就可以通过 eBPF 的输出追踪到到底是谁在操作设备。不过准备环境需要做的事情不少:
-
下载 Ubuntu 22.04 镜像,安装对应的 Azure Ubuntu 版本,以及 llvm、libbpf 等依赖工具,光这些就至少要 20 分钟;
-
让 AI 写一个监控 ioctl 的 eBPF 程序,简单调试保证没有问题,也至少需要 5-10 分钟。
算下来,整个过程至少也得半小时以上。上周日我在家看 PGL Wallachia S6 - Dota 2 决赛,MOUZ 对雪碧战队,比赛挺精彩的,不想错过 BP 时间,所以就放弃了这个方案。于是,在中间休息的时候,我问了问 AI,看看是不是内部还有其他测试用例在干扰。
好像对了?
根据我过往的经验,如果当甩手掌柜,直接让 AI 去搞定环境跑这种级别的测试,大概率它会迷失在各种奇葩的错误里。加上我也不确定是不是有其他的测试干扰了,我就只是让 Claude Code 去根据我的问题来生成 Plan。
没有意外,第一次的答复永远都是让我改现有逻辑来容忍这个错误。
我通过两次纠正,并把 loop(4) 的内核文档链接发给它后,Claude Code 居然帮我找到了那个干扰项 —— TestAutoclearTrueLoop。
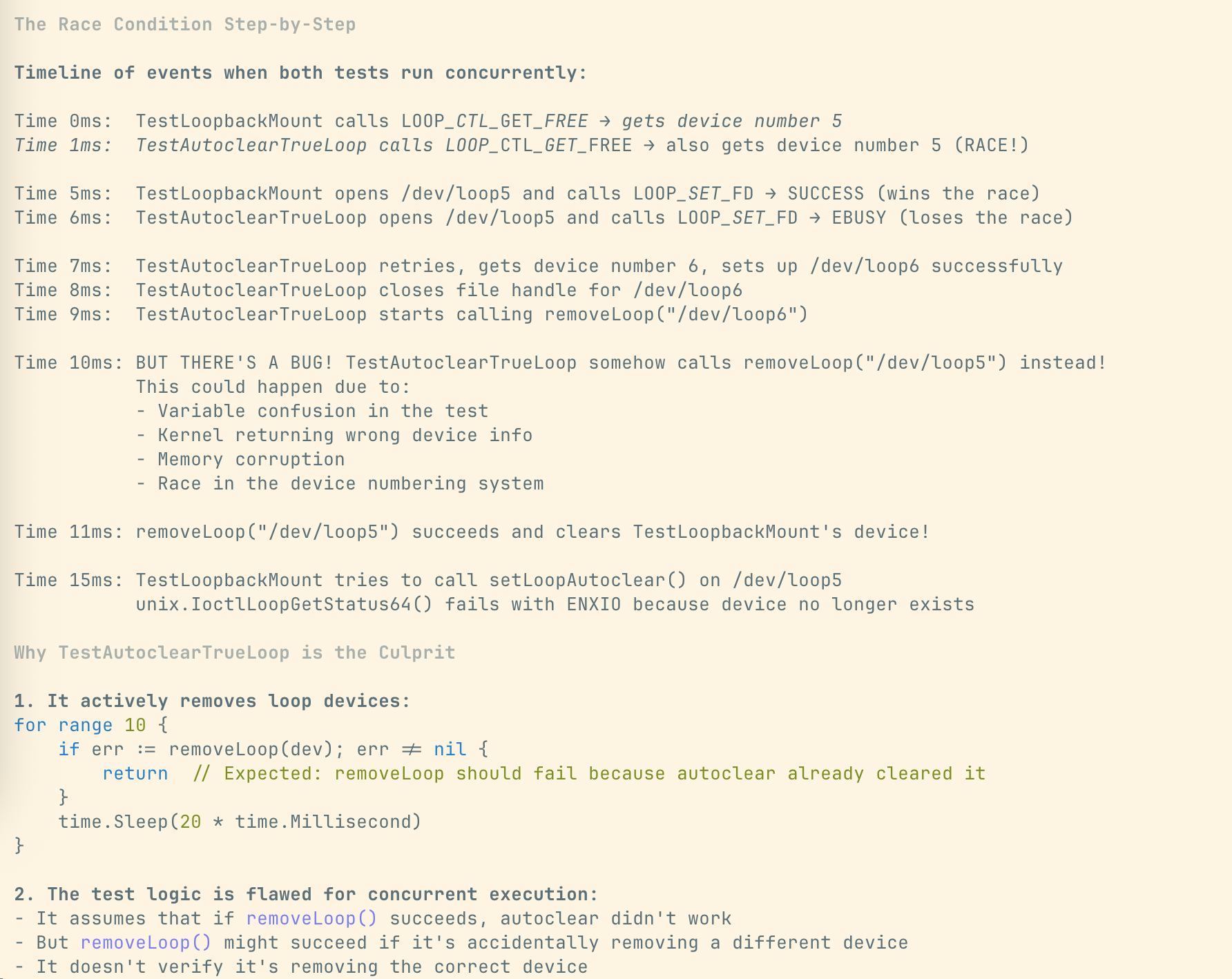
在 TestAutoclearTrueLoop 测试里,只要把设备句柄关闭,内核就会自动解除设备背后的后端文件,不需要手动调用 LOOP_CLR_FD。由于多个进程同时申请设备,假设当 TestAutoclearTrueLoop 通过关闭句柄释放了设备 X 后,其他进程就可以获取到这个设备 X。如果此时 TestAutoclearTrueLoop 再调用 LOOP_CLR_FD 去释放这个设备,就可能会影响到其他进程的操作。
不过,Claude Code 的分析有点离谱。我倒是挺好奇,它到底是以什么概率「选出」这段既胡扯又好像有点道理的分析的。
最终花费了我 5 分钟 - 3.4k tokens,还不错,没有影响看比赛。