Debug Log #1: From Containerd -EBUSY to ETCD bbolt Corruption
September 21, 2025
我打算开一个 Debug Log 系列,把平时在开源项目或生产环境里遇到的有趣问题记录下来。作为系列的第一篇,我想分享近期的两次排查经历:一次是 Containerd 临时挂载点残留,另一次是 ETCD 数据库损坏。
-EBUSY 导致临时挂载点残留
Netflix 工程师 halaney 在 Containerd 社区提交了一个问题 #12139:他们在测试环境中遇到了大量的 Idmappings 临时挂载点残留问题,几乎在并发创建容器时必现。据了解,Netflix 计划升级到 Containerd v2.0.x,这个问题成为了升级的障碍。他们内部已经通过使用 MNT_DETACH - lazy umount 的方式来规避。不过,我个人并不喜欢这种做法,因为它并没有真正解决问题本身。
前几年,我曾遇到一个「黑科技」日志采集方案——它会扫描 /run/containerd 目录下的挂载点,也就是容器的根目录,并长期持有容器根目录下的日志文件句柄,导致出现 -EBUSY 错误而无法清理容器挂载点,从而出现残留。业务为重,只能妥协,加上 MNT_DETACH :)。过往社区也出现过类似问题,但最终发现都是安全软件间歇性扫描导致的。因此一开始排查这个残留问题时,我会下意识地认为这可能是「环境」问题。
我当时怀疑的对象是 systemd.mount。每当 host mount_namespace 出现新的挂载点时,systemd 就会生成一个 mount.unit。比如当你运行 docker run -d busybox sleep 1d 时,你会发现会有一个这样奇葩的 mount.unit。老实说,我并不知道这东西的实际作用 :)
$ sudo systemctl list-units | grep var-lib-docker
var-lib-docker-overlay2-9643eb3cca86f8de7ac881124eb01ce10d3af44872f246e196a1cfe9e0ec6753-merged.mount loaded active mounted /var/lib/docker/overlay2/9643eb3cca86f8de7ac881124eb01ce10d3af44872f246e196a1cfe9e0ec6753/merged
$ sudo systemctl status var-lib-docker-overlay2-9643eb3cca86f8de7ac881124eb01ce10d3af44872f246e196a1cfe9e0ec6753-merged.mount
● var-lib-docker-overlay2-9643eb3cca86f8de7ac881124eb01ce10d3af44872f246e196a1cfe9e0ec6753-merged.mount - /var/lib/docker/overlay2/9643eb3cca86f8de7ac881124eb01ce10d3af44872f246e196a1cfe9e0ec6753/merged
Loaded: loaded (/proc/self/mountinfo)
Active: active (mounted) since Sat 2025-09-20 22:51:06 EDT; 6min ago
Where: /var/lib/docker/overlay2/9643eb3cca86f8de7ac881124eb01ce10d3af44872f246e196a1cfe9e0ec6753/merged
What: overlay
通过 opensnoop-bpfcc 和 bpftrace 等工具观察各种可能的系统调用,但 systemd.mount_process_proc_self_mountinfo 只是读取了 /proc/self/mountinfo,并不是问题的根源。后来我又花了不少时间研究 runc 相关逻辑,发现 runc 做了很多保护性处理,确保挂载点传播不会引发问题。最后只能回过头来看 Containerd 的代码了。
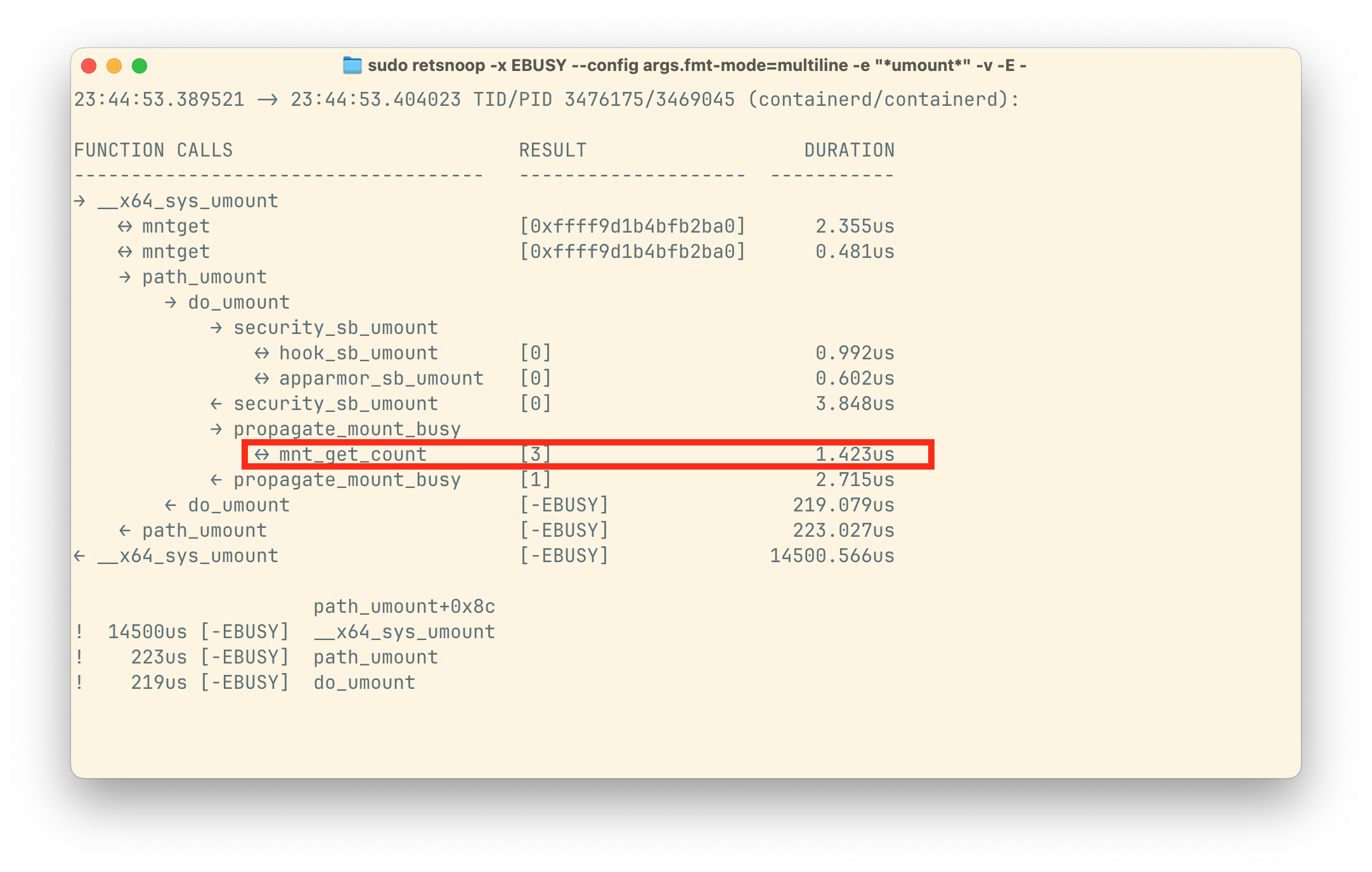
从 retsnoop 的结果来看,mnt_get_count 在 propagate_mount_busy 函数中返回了多个引用(如下图所示),这很可能是因为多个文件句柄同时指向了同一个挂载点。结合此前的观察,可以排除外部进程扫描的可能性,因此这些额外引用几乎只能来源于子进程创建过程。
IDmapping 是在挂载点上建立一个 UID/GID 映射层,使同一份数据在不同目录下呈现不同的所有者身份,具体细节可以查阅 containerd 1.7: UserNamespace Stateless Pod。IDmapping 的挂载流程如下:
- Step 1:通过 open_tree(2) 复制一份源目录的挂载子树,并获得一个指向该子树的文件句柄。
- Step 2:通过 mount_setattr(2) 系统调用修改挂载子树的属性。主要利用 user_namespace 引用来调整 UID/GID 映射。
- 例如,源目录所有者是 root,我们可以映射成用户 1000。
- Step 3:通过 move_mount(2) 系统调用将挂载子树移动到目标目录,这时挂载点形成。
- Step 4:关闭文件句柄。
在第三步成功返回后,该文件句柄会指向目标目录(即挂载点)。因此,在关闭前,它可能被复制到子进程中,例如通过 clone(2) 系统调用。即使 Containerd 在第一步中使用了 OPEN_TREE_CLOEXEC,在执行 execve(2) 之前,子进程仍会持有挂载点的句柄。如果这时调用 umount,就会触发 EBUSY 错误。
此外,第二步需要 Containerd 通过一次 ptrace re-exec 获取 user_namespace 引用。这意味着在并发创建容器时,目标挂载点的文件句柄很容易被复制到 Containerd 的子进程中。当然,调用二进制 CNI 以及启动 contained-shim 同样也会触发复制行为。因此,mnt_get_count 返回高引用数也就可以理解了。由于 open_tree(2) 在挂载时必须生成文件句柄,这一问题基本无法避免。最终的解决方案只能依靠多次重试,毕竟 clone(2) 与 execve(2) 之间的时间窗口相对较小。后续可以通过 mount plugin 统一管理所有挂载点,并借助 GC 机制从根本上解决残留问题。
在这里,我强烈推荐使用 retsnoop 来排查 Linux 内核中的系统调用错误。即便不是内核开发者,也可以通过全局检索 Linux 源代码,并结合 retsnoop 提供的调用栈信息,高效地进行定位与分析。
panic: assertion failed: Page expected to be: 5
ETCD 社区最近将故障注入测试迁移到了 antithesis 产品上。该产品会在测试运行过程中随机注入网络丢包、网络连通性中断以及 CPU 限流等故障。文档 中并未说明具体实现方式,但由于 ETCD 测试基于 docker-compose,最直观的 CPU 限流手段就是通过 cgroup 来完成。
在迁移过程中发现,ETCD Member 会接收到损坏的 snapshot(见 #20271),如下输出所示。这表明 bbolt 存储结构中出现了错误的引用。ETCD 社区过去也曾遇到过许多类似的数据库损坏问题,其中大多数由断电引起。由于对 antithesis 环境缺乏深入了解,起初很容易将其误认为是网络故障导致的错误。
panic: assertion failed: Page expected to be: 5, but self identifies as 0
goroutine 8052 [running]:
go.etcd.io/bbolt/internal/common.Assert(...)
go.etcd.io/[email protected]/internal/common/verify.go:65
go.etcd.io/bbolt/internal/common.(*Page).FastCheck(0x7f16ce802000, 0x5)
go.etcd.io/[email protected]/internal/common/page.go:83 +0x1d9
go.etcd.io/bbolt.(*Tx).page(0xc0010a31d0?, 0xc0002992e8?)
go.etcd.io/[email protected]/tx.go:598 +0x7b
go.etcd.io/bbolt.(*Tx).forEachPageInternal(0xc000c71340, {0xc0010a31d0, 0x1, 0xa}, 0xc0002993a0)
该测试过程主要通过注入网络故障和 CPU 限流来触发 Follower 节点落后于 Leader 日志进度的情况。随后,Leader 会发送完整数据库快照(snapshot)以完成同步。除此之外,测试还会以高频率对所有 Member 进行 defragment 操作。
这个问题已经放置一段时间,没有太大进展,因为大家普遍认为是环境问题。后来抱着试一试的心态去查看 ETCD Member 日志。只能说这种方法比较「原始」,一旦日志记录不够详尽,没有关键的信息,就几乎是在浪费时间。只能说运气还不错,大部分 debug 信息都输出了。
Follower 收到的数据库快照显示 Index 为 74,并且确认已落盘。然而,当该 Follower 从该快照恢复时,却显示 Index 为 67。由此可以确认,这不是环境问题,而是 ETCD 内部存在 Race condition。
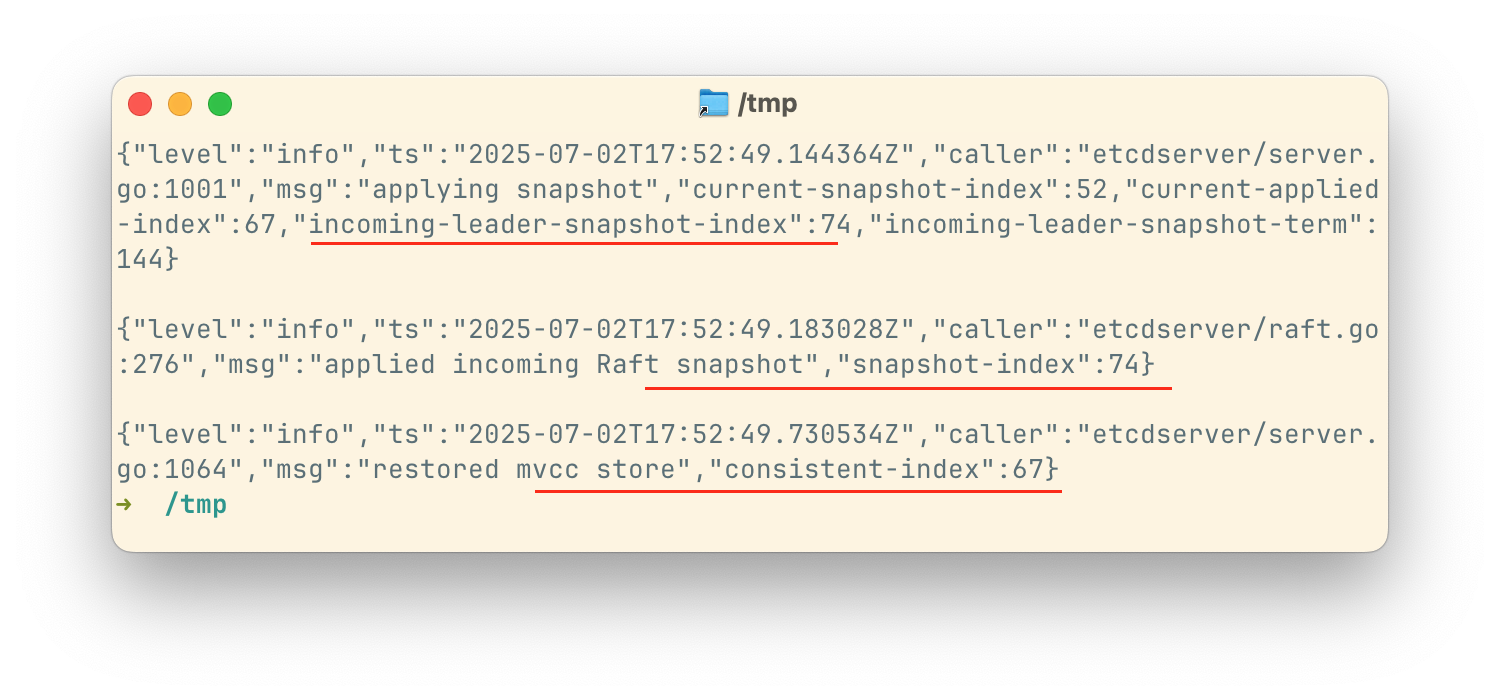
这个 race condition 是由 defragment 操作触发的。在 ETCD 使用接收的快照之前,它会通过 rename(2) 覆盖当前正在使用的数据库文件。事件时间线如下:

需要解释的是:如果一个进程保持着一个文件句柄,即使这个文件被删除或覆盖,该进程依然可以继续通过这个句柄操作文件。一个最直观的场景是:业务进程写了大量日志,而磁盘空间几乎耗尽,此时需要清理日志文件,但业务进程不能重启。如果直接删除日志文件,文件并不会真正释放空间,因为业务进程仍然持有文件句柄,可以继续写入数据。正确的做法是使用 truncate(1) - truncate -s 0 log 或者是 cat /dev/null > log,保留原文件的 inode,将文件大小强制清零,从而释放磁盘空间,同时保证业务进程继续写入日志而不受影响。
同样地,在 T10 之后,ETCD Member 会将后续的变化写入到一个已经被覆盖的文件中。到这一步,其实问题不大——重启后的 ETCD Member 仍然落后于其他 Member,仍可以继续接收新的快照。然而,从 T10 之后,它开始成为 Leader。在测试的后期,它需要向其他 Member 发送快照,这时问题就暴露出来了。
在发送快照时,ETCD 利用了多版本并行控制 (MVCC) 特性,只会发送当前 bbolt 只读事务对应的版本。bbolt 数据库的前两页保存着整棵 B+Tree 的根节点引用,因此在发送快照前,ETCD 会先发送当前事务版本的根节点引用,然后再读取数据库的其余部分。即使在此过程中有新的事务提交,也不会影响当前版本的数据,从而保证快照的一致性,如下图所示。这里有一个前提,文件不能被覆盖。
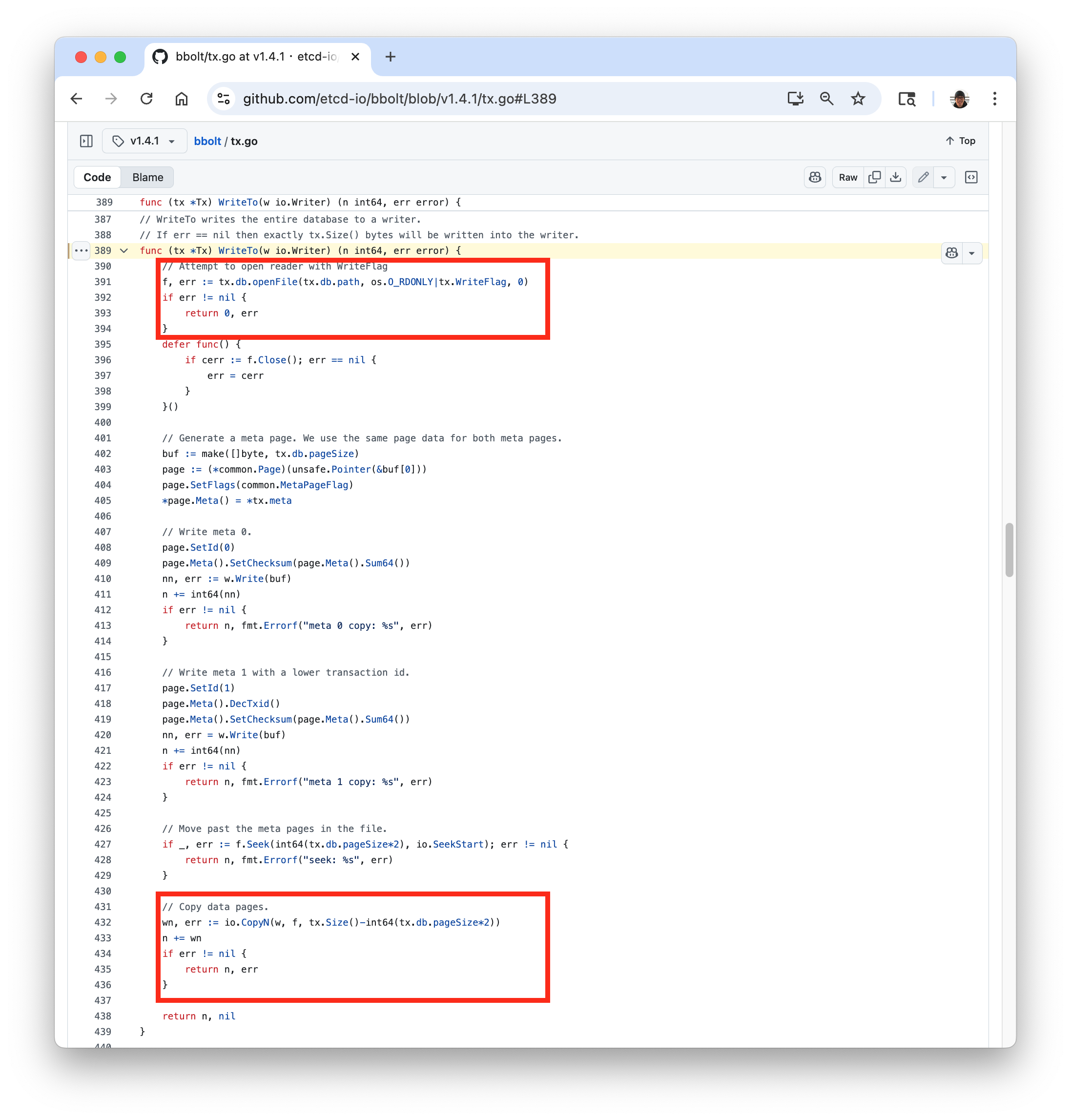
在测试过程中,ETCD 的 snap.db 文件已经被 T8 时刻的操作覆盖,其内容与正在使用的、已被删除的文件完全不同。值得注意的是,bbolt.WriteTo 并没有使用原有的文件句柄,而是重新打开了一个新的句柄。由于前两页存储的根节点引用与实际存储内容不一致,最终会导致 bbolt 初始化失败并触发 panic。
为解决该问题,ETCD 需要避免 Race Condition(见 #20553),而 bbolt 则必须确保传输的文件内容保持一致(见 #1057)。不过,对于 #1057,实际上也可以考虑重新打开一份已被删除文件的句柄,因为 io.Copy 可以利用 splice(2) 实现 Zero-Copy。当然,在 ETCD 发送快照时,中间存在一层 Copy,此时无法使用 splice(2),因此使用 pread(2) 也还行吧。
diff --git a/tx.go b/tx.go
index f32a209..d6c2e85 100644
--- a/tx.go
+++ b/tx.go
@@ -5,8 +5,10 @@ import (
"fmt"
"io"
"os"
+ "path/filepath"
"runtime"
"sort"
+ "strconv"
"strings"
"sync/atomic"
"time"
@@ -390,7 +392,7 @@ func (tx *Tx) Copy(w io.Writer) error {
// If err == nil then exactly tx.Size() bytes will be written into the writer.
func (tx *Tx) WriteTo(w io.Writer) (n int64, err error) {
// Attempt to open reader with WriteFlag
- f, err := tx.db.openFile(tx.db.path, os.O_RDONLY|tx.WriteFlag, 0)
+ f, err := tx.db.openFile(filepath.Join("/proc", strconv.Itoa(os.Getpid()), "fd", strconv.Itoa(int(tx.db.file.Fd()))), os.O_RDONLY|tx.WriteFlag, 0)
if err != nil {
return 0, err
}
最后
我尝试用 AI 来排查这两个问题,但可能是使用方式不对。即使输入了大量信息,把我的分析步骤都写了出来,依然得不到理想的结果。最接近的一次是,它认为我没有关闭 open_tree(2) 返回的句柄,于是它在代码里加了一行关闭操作。结果却导致对同一个句柄进行了两次关闭,最后它又开始聚焦在为什么会发生新的错误…