Previewing Rebase Snapshots in containerd v2.2.0
October 31, 2025
containerd 社区近期发布了 v2.2.0-rc.0 版本,预计将在亚特兰大 KubeCon 前正式 GA。在正式发布之前,我想先分享其中的一个特性 – Rebase Snapshot,它可以显著提升大型镜像的下载效率。
Snapshot Model
在 Open Container Initiative (OCI) 镜像标准中,每次对容器镜像的修改都会生成一个镜像层(Image Layer)。每层只包含新增、删除或修改的文件,层与层之间互相依赖,就像 Git 的提交记录一样,后一层是基于前一层构建的。
容器运行时(消费端)会按照依赖顺序依次应用(或叠加)这些镜像层的数据,最终组合形成容器进程的根文件系统。至于数据如何叠加和存储,则取决于所采用的底层存储。此外,容器进程对其根文件系统产生的变更,可以被「提交」并封装为一个新的镜像层,这是常见的镜像构建方式。
为了统一管理镜像层和容器文件系统的数据,containerd 引入了 snapshot的概念。它将这些文件系统抽象为可管理的 snapshot,并使用统一的 snapshotter 接口来对接和表达不同底层存储介质(如 OverlayFS, EROFS, OverlayBD, DevMapper 等)的实现方式。
NOTE: From 2017: containerd deep dive presentation at the containerd summit
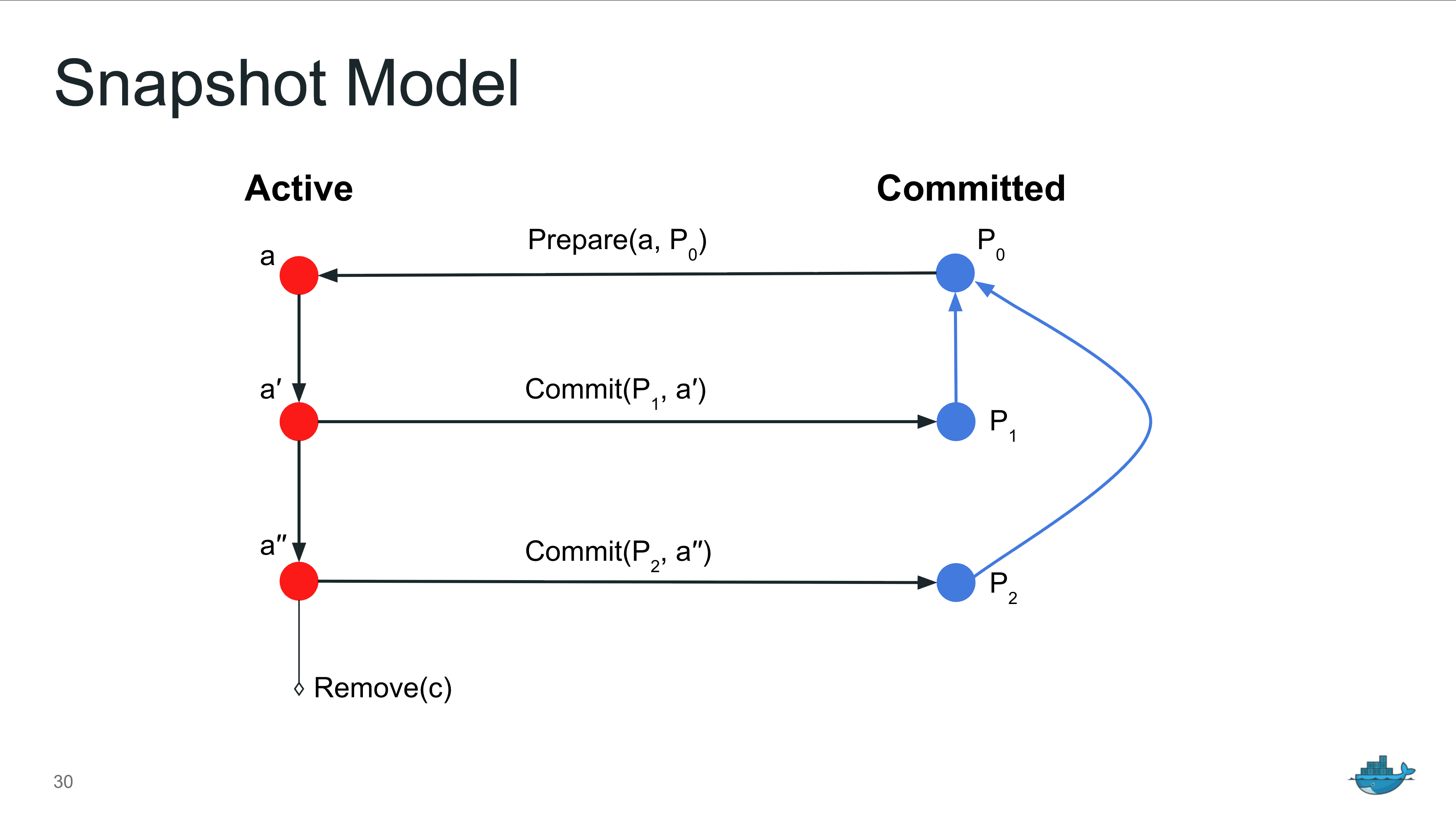
Snapshot 包含两个关键状态:
* Active:在此状态下,允许对文件内容进行添加、删除和修改等操作。
* Committed:一旦 Active Snapshot 被提交(Commit),它将转换为 Committed 状态。
原则上,处于 Committed 状态的文件内容是不可变更的。
在解压镜像层数据时,containerd 会基于上一层 snapshot 来创建新的 active snapshot。上一层 snapshot 可以为空,「通常」表达当前 active snapshot 对应着第一层。解压数据完毕后,再将其提交成 committed 状态;重复此流程直到所有镜像层都处理完毕。Snapshot 之间的依赖关系能帮助 containerd 的 GC 模块识别哪些 snapshot 已经不再被引用(orphan snapshot),从而将其安全删除。但这也意味着 containerd 必须按照顺序解压镜像。
Existing Enhancements on pulling
[v1.0.0] Initial Version
在 containerd 的最初版本(2017 年)中,镜像处理流程被设计为两个阶段:首先并发下载所有镜像层,然后按照层级关系依次解压。解压某一层时,containerd 需要先将其所有祖先 snapshot 按顺序进行 union mount,形成完整的基础视图,然后才能在此基础上应用当前层的数据。
[v1.3.0] Direct unpack support for overlayFS
Union mount 本身是一项开销较高的操作,特别是在执行卸载(umount)时更为明显。在 Linux kernel v5.10(支持 volatile 选项)之前,卸载 OverlayFS 挂载点会触发强制刷盘,写放大进一步增大了开销。而实际上,在解压 OCI 镜像层数据时,并不需要访问上一层已展开的文件内容;containerd 也无需先构建完整的文件系统视图再进行解压。
因此,从 v1.3 开始,containerd 为 overlayFS snapshotter 引入了一种优化方式:直接将镜像层解压到对应的 snapshot 目录,避免为了解压而执行 union mount。
[v1.3.0] Add simultaneous unpack support
此外,v1.3 版本实施了另一项优化:下载与解压的并行处理。containerd 现在无需等待所有镜像层下载完毕,而是在任何一层下载完成后就立即启动解压任务,以提升镜像处理的整体速度。然而,这项优化存在一个关键的局限性:镜像层的解压必须严格按照其依赖的顺序进行。这意味着即使后面的层(例如第 3 层)比前面的层(例如第 2 层)先下载完成,它也必须等待所有前置层(第 1 层、第 2 层等)下载并解压完成后才能开始处理。由于在大多数镜像结构中,较小或变更较少的层通常位于镜像的末尾,因此顺序依赖使得「并行解压」收益有限。
[v2.1.0] Multipart layer fetch
在上一个版本中,containerd 引入了同一镜像层的并发下载能力。利用 OCI Distribution 协议中支持可断点续传 - resumable pull - 的特性,containerd 会将大型镜像层切分为多个区段,多路并发下载。各区段数据在内存中按顺序重新组合,并最终写回本地磁盘,形成完整的镜像层。这一优化提升了大镜像层的下载速度,但也带来了两个限制:
* 会额外占用内存,因为数据区段需要在内存中进行拼接;
* 效果依赖区段大小配置,划分不合理会影响性能收益。
目前,大多数由 Go 编写的服务(包括容器镜像仓库)默认使用 HTTP/2 协议。然而,HTTP/2 在传输大体积数据时效率并不高,带宽利用率受限,服务端往往需要等待客户端的窗口更新(WINDOW_UPDATE),而非持续传输数据。containerd 通过多连接并发下载来缓解这一问题,本质上是在规避 HTTP/2 流控带来的性能限制。在网络质量可控的情况下,使用单连接的 HTTP/1.1 反而可能实现更高的吞吐性能。
Rebase
尽管过去的优化提升了下载效率,但一个事实没有改变:镜像层的解压仍然是按顺序进行的。为了解决这一瓶颈,Derek 在问题 Parallel Container Layer Unpacking 中提出了 Rebase Snapshot 来加速处理。
经常使用「变基」的朋友对这个词应该不陌生:在 Git 中,git rebase upstream/master 可以用来更新当前分支。它的本质是将当前分支上的提交,在最新的 master 分支基础上重新回放一遍。

NOTE: From https://git-scm.com/book/ms/v2/Git-Branching-Rebasing
同样地,支持 rebase 的 snapshotter 允许在提交时,将一个没有 parent 的 active snapshot 绑定到指定的 committed snapshot 上,如下图所示。
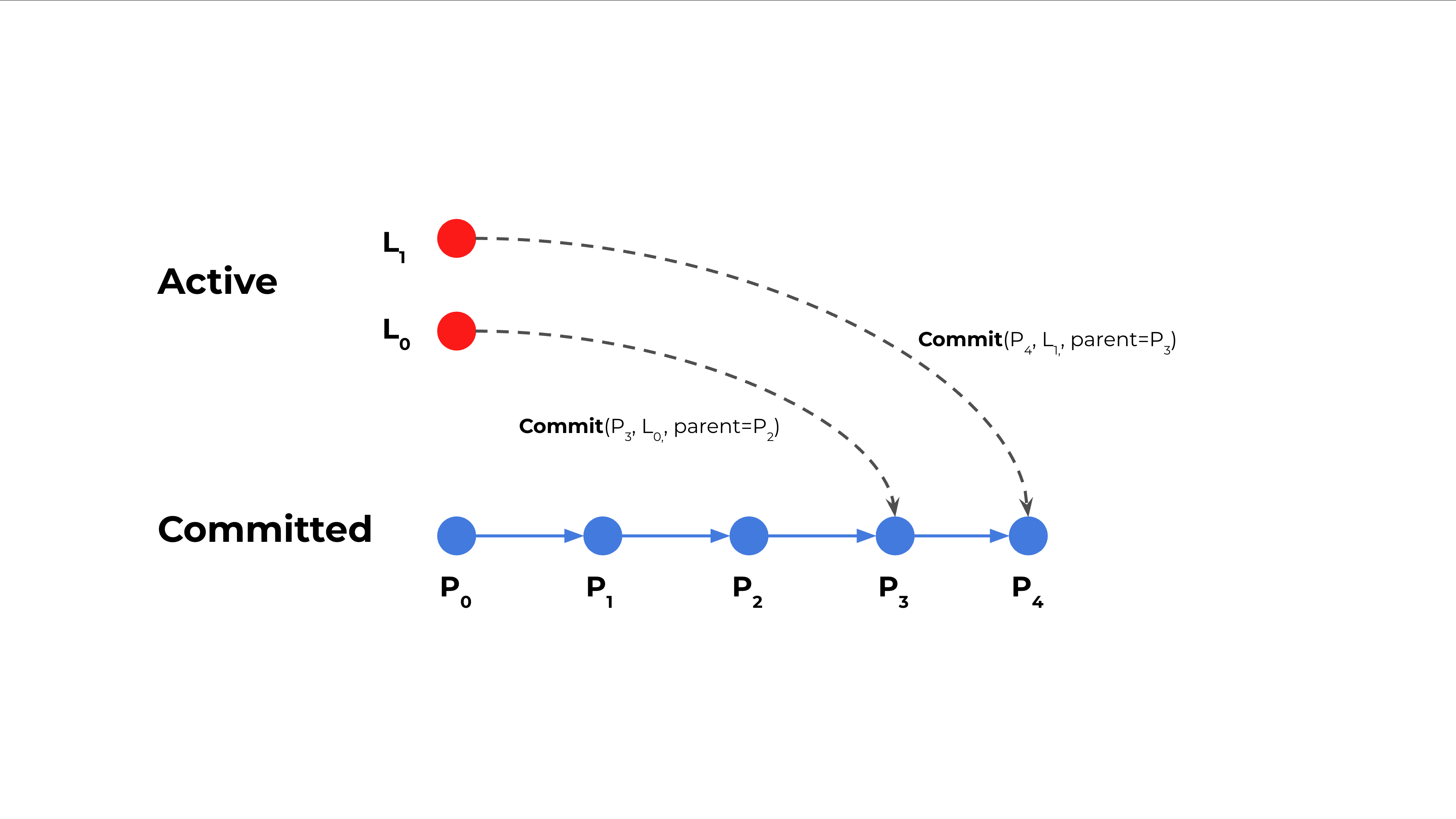
在下载镜像时,containerd 会同步解压所有镜像层,此时这些 Active snapshot 尚未指定父 snapshot。解压完成后,它们会按顺序提交,并关联到指定的父 snapshot,从而建立层之间的依赖关系。这个过程类似于 Git 的 rebase:在管理层面回放各层提交,实现了真正意义上的「同步解压」。
我在本地开发机器上测试了镜像 huggingface/transformers-pytorch-gpu:4.41.2(解压后约 17.7 GiB)的下载与解压效果,并与 containerd v2.1.4 版本进行了对比。
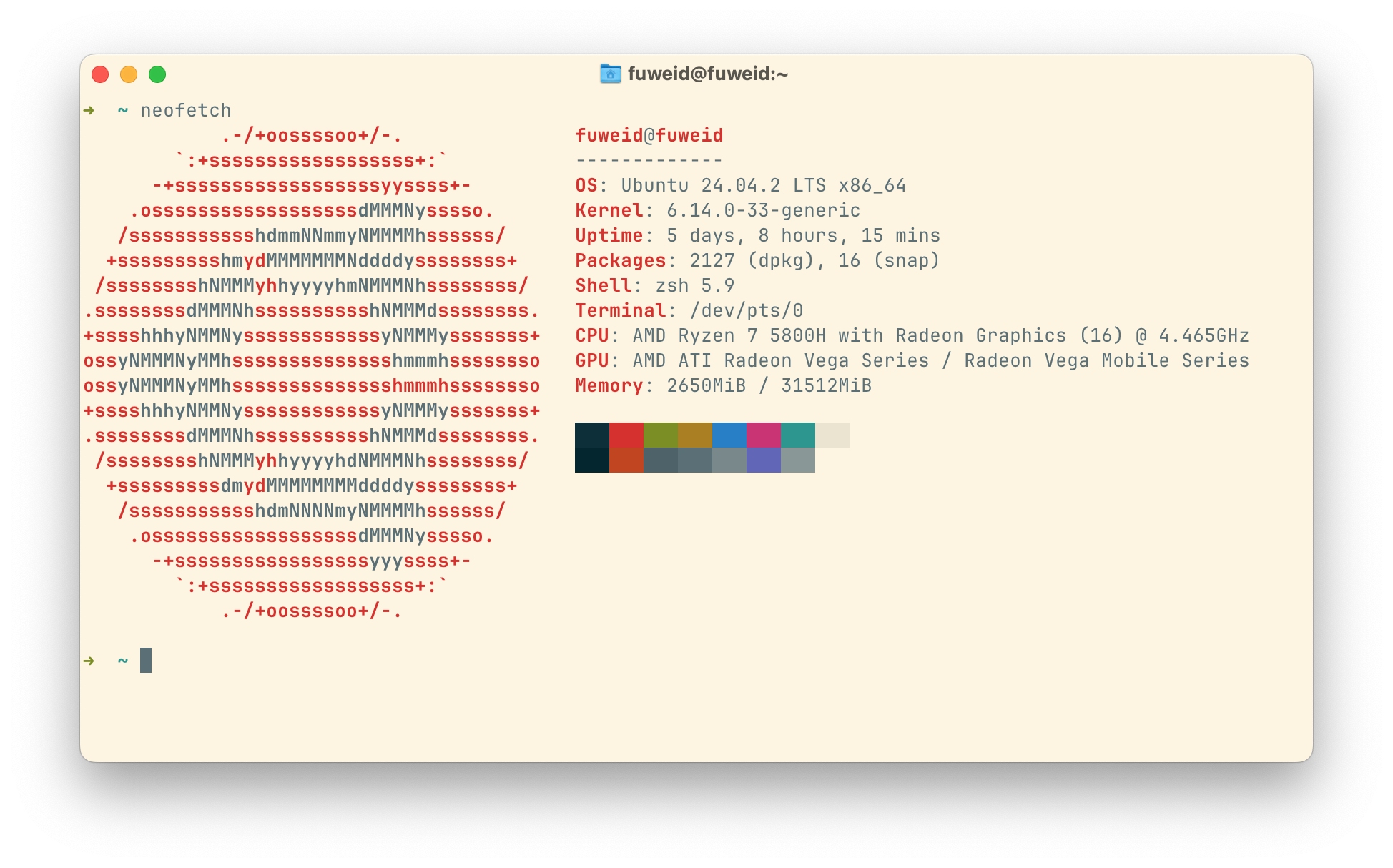
本地机器配置如下:
为了避免网络带宽的影响,我把镜像下载到本地,并传到本地运行的 registry 服务里。优化效果还是挺明显,一倍左右。
v2.1.4 需要 - 72s
- 关闭 multipart layer fetch 优化
- max_concurrent_download = 3
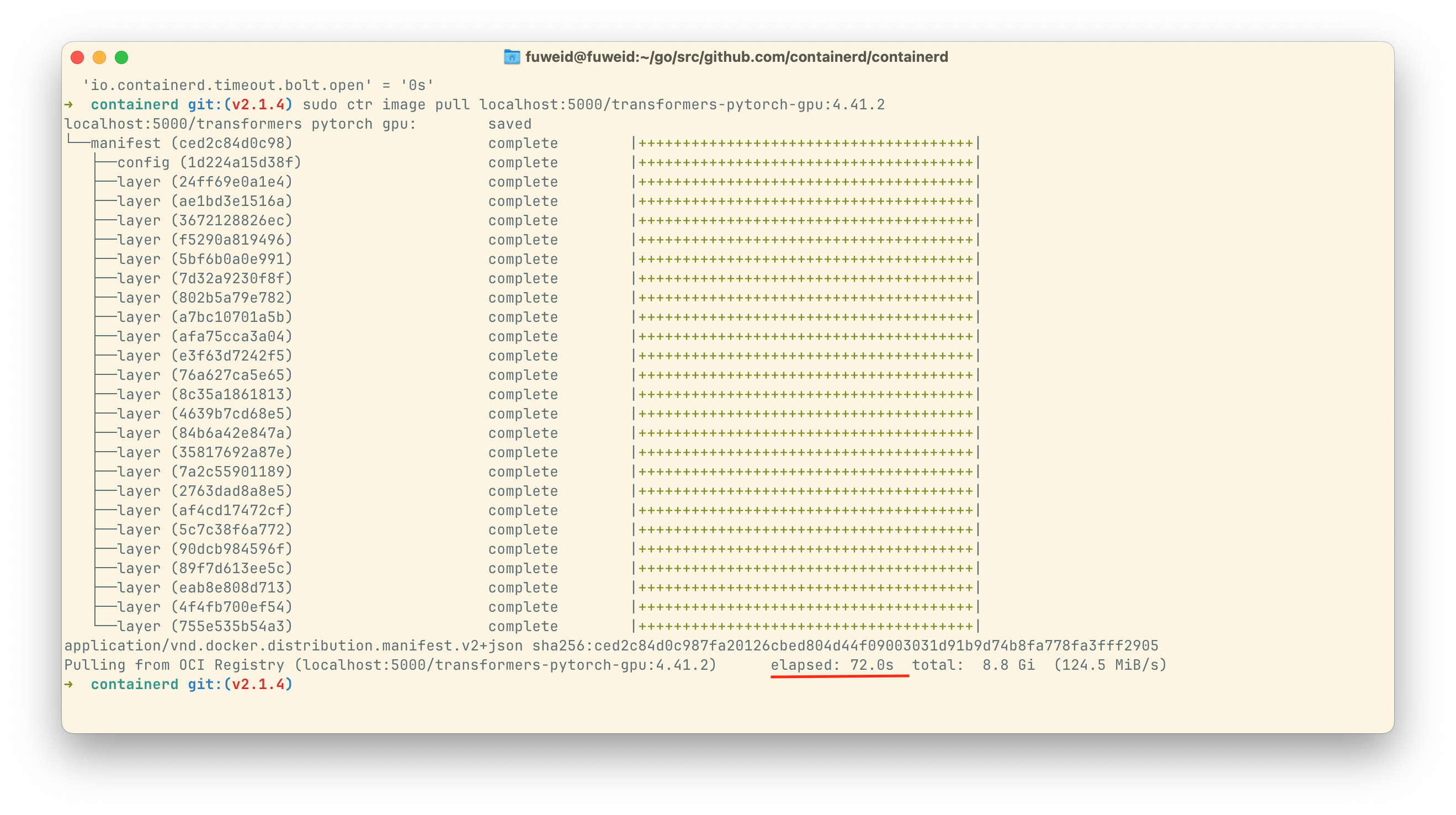
v2.2.0-rc.0 需要 - 34.7s
- 关闭 multipart layer fetch 优化
- max_concurrent_download = 3
- Max_concurrent_unpacks = 3
