[CONT] Non-Preemptible RCU soft lockup: zap_pid_ns_processes
June 10, 2024
接着上一篇 Non-Preemptible RCU soft lockup: zap_pid_ns_processes。 根据内核维护者的回复和修复补丁,已经确定是和 io_uring(7) worker 唤醒机制有关。
io_uring io-wq worker pool
根据 Redesigned workqueues for io_uring 文章的描述,io_uring 使用 workqueue 处理异步 IO 请求有局限性, 因此在 io-wq: small threadpool implementation for io_uring 补丁里开始用线程池来替代 workqueue。
当用户态进程通过 io_uring_enter(2) 系统调用提交 io 请求,io_uring 模块会将 io 请求放入到队列里, 并按需创建内核线程 io_wqe_worker 来处理请求,如下图的上半部分。
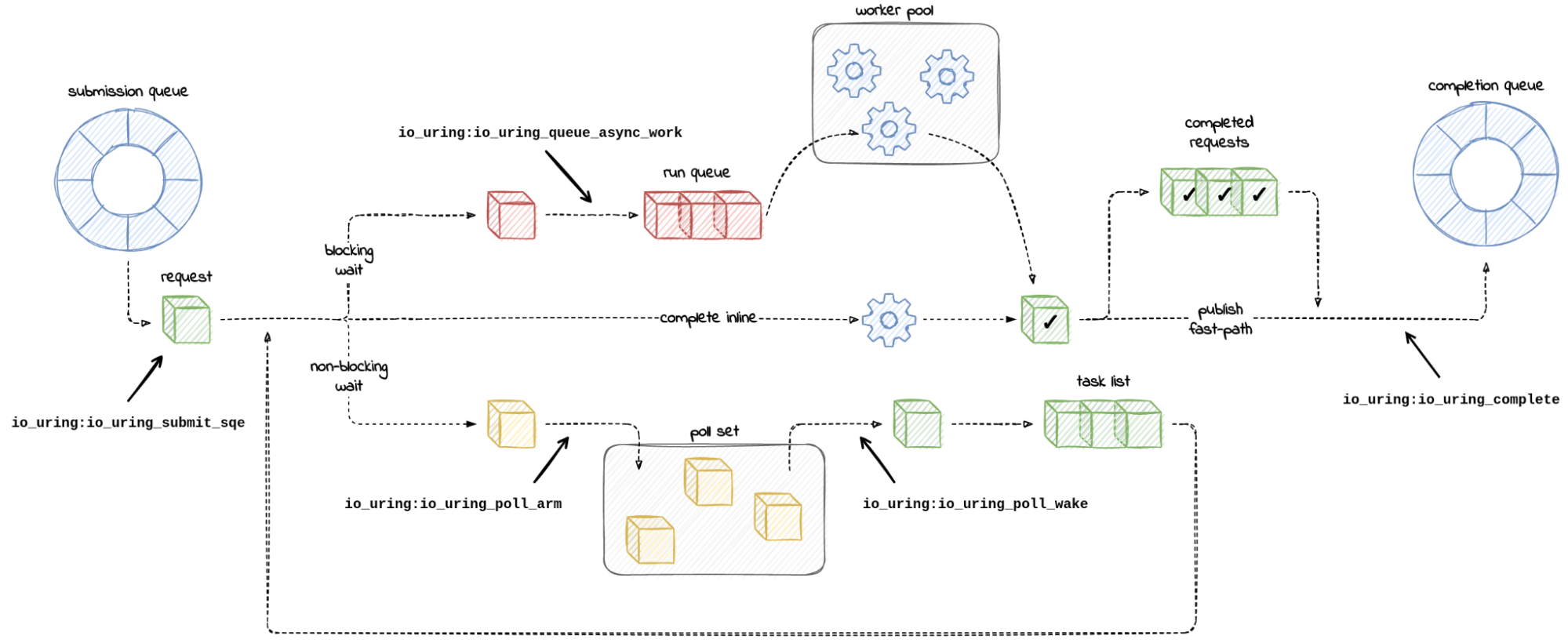
NOTE: 该图来源于 https://blog.cloudflare.com/missing-manuals-io_uring-worker-pool
以该 package.json 为例,nodejs-20.11.0 默认开启 io_uring,在 npm run done 前,nodejs 会利用 uv__iou_fs_statx 函数来获取当前文件系统的信息。
这个 io_uring statx io 请求会触发内核创建 io_wqe_worker 线程。
那么我们看下 npm run zombie 长时间运行的程序都有哪些线程。
如下图的下半部分为例,1147997 进程有两个 iou-wrk-1148006 的线程。
io_wqe_worker 线程会以调用 io_uring_enter 的线程 ID 来命名 iou-wrk-%d,
因此 iou-wrk-1148006 内核线程是由 1148006 线程创建的。

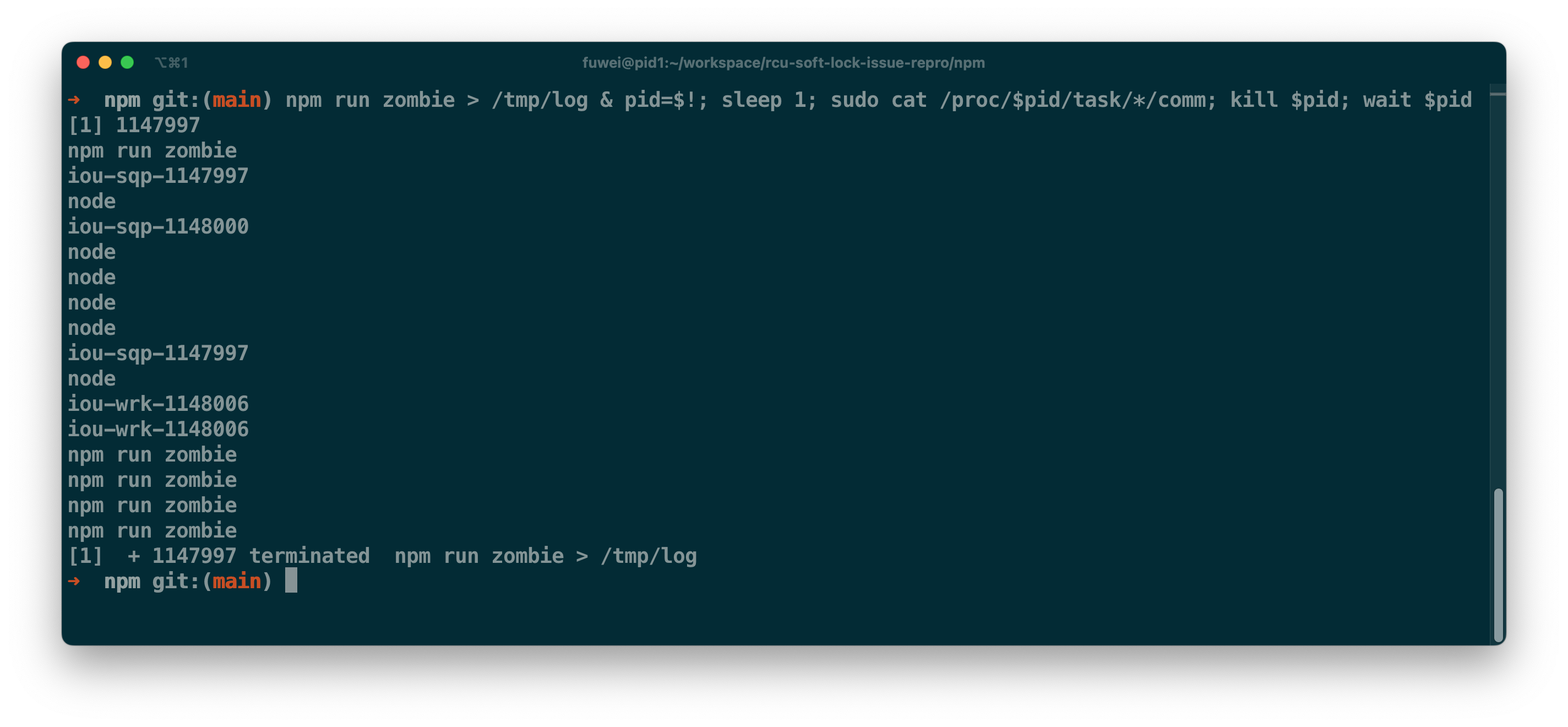
当创建 io_wqe_worker 的用户线程退出时,那么内核会在 do_exit.io_uring_files_cancel 函数里唤醒 worker 并告知它应该结束工作。
TIF_NOTIFY_SIGNAL
就目前了解到细节来看,线程的信号处理更像是调度处理(以打标记为主)。
负责发送信号的线程除了添加信号信息外,它还需要把目标线程标记上 TIF_SIGPENDING;
当目标线程准备从系统调用返回用户态时,目标线程会在 exit_to_user_mode_loop 检查 TIF_SIGPENDING 是否存在;
如有信号到来,那么线程将调用 handle_signal_work 处理信号,它有可能会回到用户态,比如用户自定义的 SIGUSR1 信号处理。
同样,io_uring 也是通过添加 TIF_SIGPENDING 标记的方式来唤醒 io_wqe_worker。
但根据 task_work: use TIF_NOTIFY_SIGNAL if available 补丁来看,
早期 io_uring 通过 jobctl 来进行信号标记,但这个方式需要对线程的 task->sighand 属性进行加锁;
当进程是多线程程序时,锁对性能的影响比较大。因此 io_uring 引入了新的标记 TIF_NOTIFY_SIGNAL 避免锁的影响。
当创建 io_wqe_worker 的线程退出后,那么该线程会把 IO_WQ_BIT_EXIT 标记成 1,
并将所有相关的 io_wqe_worker 线程都标记上 TIF_NOTIFY_SIGNAL 并唤醒让其退出。
但我们看看 io_wqe_worker 关键代码,整个过程里,该线程只有在 io_flush_signals 里有机会消除这个 TIF_NOTIFY_SIGNAL 标记,
那么 io_wqe_worker 线程是有可能带着这个标记进入到 zap_pid_ns_processes 阶段,从而导致 CPU 无法运行其他线程。
// v5.15.160
static int io_wqe_worker(void *data)
{
// ...
// IO_WQ_BIT_EXIT=1 表示 worker 应该结束工作
while (!test_bit(IO_WQ_BIT_EXIT, &wq->state)) {
// ...
// 清除 TIF_NOTIFY_SIGNAL
if (io_flush_signals())
continue;
// 没任务时,将进入睡眠态
ret = schedule_timeout(WORKER_IDLE_TIMEOUT);
// 检查当前线程是否有以下两个标记
// TIF_SIGPENDING
// TIF_NOTIFY_SIGNAL
if (signal_pending(current)) {
struct ksignal ksig;
// 取出信号
if (!get_signal(&ksig))
continue;
break;
}
// ...
}
// ...
// 调用 do_exit(0);
io_worker_exit(worker);
}
io_wqe_worker thread is last one in init
现在有一个进程 X,它运行在新的 pid_namespace(7) 以及 mount_namespace(7) 里。 它只有两个线程,它们分别是 X-1 以及 X-iou-wrk-1。除此之外,X 还有一个孩子进程 Y。 进程 Y 和 X 运行在相同的 namespace 下。
进程 X 作为它所在 pid_namespace 里是 一号进程。
当进程 X 主线程 X-1 退出时,它会给 X-iou-wrk-1 线程发送 SIGKILL 信号并唤醒它。
如果 X-iou-wrk-1 线程还没完全从 io_wqe_worker 上下文里结束,线程 X-1 有机会给 X-iou-wrk-1 标记上 TIF_NOTIFY_SIGNAL。
如果 X-1 提前结束, X-iou-wrk-1 将会是一号进程里唯一非 zombie 线程, 它将负责清理在这个 pid_namespace 下的所有进程,比如这里的进程 Y。 线程 X-iou-wrk-1 将进入 zap_pid_ns_processes 来清理进程 Y。
// v5.15.160
void zap_pid_ns_processes(struct pid_namespace *pid_ns)
{
// ...
// 给当前 pid_namespace 下的所有线程发送 SIGKILL
// 根据前面的假设,这里只有进程 Y。
rcu_read_lock();
read_lock(&tasklist_lock);
nr = 2;
idr_for_each_entry_continue(&pid_ns->idr, pid, nr) {
task = pid_task(pid, PIDTYPE_PID);
if (task && !__fatal_signal_pending(task))
group_send_sig_info(SIGKILL, SEND_SIG_PRIV, task, PIDTYPE_MAX);
}
read_unlock(&tasklist_lock);
rcu_read_unlock();
// 给进程 Y 发送 SIGKILL 后,还需要回收 Y
do {
// 清理掉 TIF_SIGPENDING
// 如果有新来的 TIF_SIGPENDING 信号
// 那么 kernel_wait4 就有机会释放 CPU
clear_thread_flag(TIF_SIGPENDING);
rc = kernel_wait4(-1, NULL, __WALL, NULL);
} while (rc != -ECHILD);
// ...
}
kernel_wait4.do_wait 遇到没有可以回收的线程时,它会判断是否需要处理信号。 如果没有信号需要处理,那么它将调用 schedule 来释放当前 CPU。 在没有开启抢占模式的内核下,进入内核态的线程只能主动释放 CPU,比如结束系统调用或者主动调用 schedule。 不然它将长期霸占所在的 CPU。
// v5.15.160
static long do_wait(struct wait_opts *wo)
{
// ...
notask:
retval = wo->notask_error;
if (!retval && !(wo->wo_flags & WNOHANG)) {
retval = -ERESTARTSYS;
// 没有可以回收线程,比如 D 状态的线程
// 假设没有信号需要处理,那么线程主动释放 CPU
if (!signal_pending(current)) {
schedule();
goto repeat;
}
}
// ...
}
然而线程 X-iou-wrk-1 身上一直有 TIF_NOTIFY_SIGNAL 标记,导致 signal_pending 一直返回 True, 它永远都走不到 schedule 这个函数。
而进程 Y 收到信号后退出,它是最后一个引用 mount_namespace 的进程,
它将负责回收 mount_namespace 相关的资源,并进入到 synchronize_rcu_expedited 函数。
而 synchronize_rcu_expedited 要求所有 CPU 都要上报静止态,也就是至少发生过一次上下文切换。
但线程 X-iou-wrk-1 并不会释放 CPU,所以进程 Y 无法从 synchronize_rcu_expedited 中离开从而长期处于 D 状态,形成了一个死锁。
# 进程 Y
$ sudo cat /proc/2522605/task/2522645/stack
[<0>] synchronize_rcu_expedited+0x177/0x1f0
[<0>] namespace_unlock+0xd6/0x1b0
[<0>] put_mnt_ns+0x73/0xa0
[<0>] free_nsproxy+0x1c/0x1b0
[<0>] switch_task_namespaces+0x5d/0x70
[<0>] exit_task_namespaces+0x10/0x20
[<0>] do_exit+0x2ce/0x500
[<0>] io_sq_thread+0x48e/0x5a0
[<0>] ret_from_fork+0x3c/0x60
[<0>] ret_from_fork_asm+0x1b/0x30
$ sudo cat /proc/2522605/task/2522645/status
Name: iou-sqp-2522605
State: D (disk sleep)
# ...
后续任何回收 mount_namespace 的操作都将卡死,只有重启系统才可以缓解。
这个问题的修复也比较简单,就是在进入 kernel_wait4 之前清理掉 TIF_NOTIFY_SIGNAL 标记即可。
diff --git a/kernel/pid_namespace.c b/kernel/pid_namespace.c
index dc48fecfa1dc..25f3cf679b35 100644
--- a/kernel/pid_namespace.c
+++ b/kernel/pid_namespace.c
@@ -218,6 +218,7 @@ void zap_pid_ns_processes(struct pid_namespace *pid_ns)
*/
do {
clear_thread_flag(TIF_SIGPENDING);
+ clear_thread_flag(TIF_NOTIFY_SIGNAL);
rc = kernel_wait4(-1, NULL, __WALL, NULL);
} while (rc != -ECHILD);
Summary
如果你是从事容器开发的朋友,应该对函数 zap_pid_ns_processes 不陌生,遇到就只能献上重启大法 QQ。 本次分享的问题只有使用 io_uring 的容器应用才会遇到。对于 nodejs 而言,如果 io_uring 不是刚需,可以考虑用 UV_USE_IO_URING=0 关闭掉。
最后,根据内核大佬的说法,zap_pid_ns_processes 这个函数已经遇到过很多问题,不排除还有其他坑 T.T。