Non-Preemptible RCU soft lockup: zap_pid_ns_processes
June 6, 2024
分享一个最近遇到的容器问题吧,虽然还不知道该怎么解决,但已经发信给内核社区寻求帮助了。
[RCU] zombie task hung in synchronize_rcu_expedited
这是一个关于 zap_pid_ns_processes.kernel_wait4 死循环的问题,因为没有开启内核的 抢占模式,
似乎处于 zap_pid_ns_processes.kernel_wait4 调用栈的线程没法进行上下文切换,导致 synchronize_rcu_expedited 卡死,
容器无法正常释放 mount_namespace。目前我可以在 v5.15/v6.1/v6.5/v6.9/v6.10-rc2 内核版本上复现该问题,
而且在 v5.15 内核上尤其容易复现。
注: 编译条件可以查看文章的最后。
Non-Preemptible RCU synchronize_rcu_expedited
RCU 是一个极其复杂的话题,本节关于 RCU 的描述会存在不准确或者不正确的可能性。 本人仅在复现 soft lockup 问题上表达自己对不可抢占 RCU 的一些理解,对于更官方或者更准确的表达,应该查阅 RCU 的官方文档。
Read-Copy-Update 是内核里对并发读比较友好的同步机制。与传统的互斥锁不同,RCU 利用 CPU 上下文切换来反馈进程是否离开了临界区。
rcu_read_lock()
// RCU read-side critical section
rcu_read_unlock()
RCU 临界区内不可自行调用 schedule 来进行 CPU 线程的上下文切换。
因此非抢占模式下的 CPU 线程发生上下文切换时,比如内核态返回用户态或者执行其他进程时,那么当前 CPU 一定离开了 RCU 临界区。
内核没有内存垃圾回收机制,因此当受 RCU 临界区保护的数据需要更新时,更新者要负责回收正在被 RCU 临界区访问的老数据。
因此 RCU 的更新操作分两个阶段:删除 和 回收。
// https://lwn.net/Articles/262464/#Publish-Subscribe%20Mechanism
q = kmalloc(sizeof(*p), GFP_KERNEL);
*q = *p;
q->b = 2;
q->c = 3;
// Removal
list_replace_rcu(&p->list, &q->list);
synchronize_rcu();
// Reclamation
kfree(p);
删除操作本质上是赋值,表示当前的数据已指向新的内存地址。 但更新前的数据内存可能正在被其他 CPU 线程访问,更新者无法直接释放这块内存,它需要等待所有 CPU 线程都离开了临界区。
在具体实现细节里,每一个 CPU 线程都有 Quiescent State 标志。
当 CPU 线程正在访问 RCU 临界区时,我们称之为 活跃态;当 CPU 离开临界区后并发生上下文切换时,那么我们称之为 静止态。
RCU 数据更新者 在更新完数据后,它需要调用 synchronize_rcu 函数等待所有 CPU 线程上报静止态,这段等待时长称之为 Grace Period 宽限期。
如下图所示,CPU 1 和 CPU 2 分别离开 Reader 1-1 和 Reader 2-1 临界区后上报静止态;
而 CPU 3 启发宽限期时,CPU 0 已经属于空闲状态,因此后续 Reader 0-2 临界区访问的是新的数据内存,不存在释放内存的风险。
因此宽限期在 CPU 2 上报静止态后结束。 宽限期后并没有代码会继续访问老的数据内存,CPU 3 可以放心释放这段内存空间。

synchronize_rcu 主动等待其他 CPU 线程上报静止态,可能存在长延迟的情况。
内核提供了 synchronize_rcu_expedited 函数来加速其他 CPU 线程上报静止态的效率。
synchronize_rcu_expedited 会主动给 non-idle no-hz CPU 线程发送 IPI 中断。
以 v5.15 内核代码为例,synchronize_rcu_expedited 会启动 kernel worker 去运行 wait_rcu_exp_gp, 然后等待所有的 CPU 线程上报静止态。
wait_rcu_exp_gp 会调用 smp_call_function_single 给 CPU 线程发送 IPI 中断,随后对应的 CPU 线程会进入到 rcu_exp_handler。
在 rcu_exp_handler 的逻辑里,如果发现 CPU 线程原本属于空闲状态,那么它将立刻上报静止态。
如果不是,那么它将当前进程标记成可抢占,一旦该进程满足被抢占条件后,该 CPU 线程就会出现上下文切换并上报静止态。
// v5.15.160
/* Request an expedited quiescent state. */
static void rcu_exp_need_qs(void)
{
__this_cpu_write(rcu_data.cpu_no_qs.b.exp, true);
/* Store .exp before .rcu_urgent_qs. */
smp_store_release(this_cpu_ptr(&rcu_data.rcu_urgent_qs), true);
set_tsk_need_resched(current);
set_preempt_need_resched();
}
/* Invoked on each online non-idle CPU for expedited quiescent state. */
static void rcu_exp_handler(void *unused)
{
struct rcu_data *rdp = this_cpu_ptr(&rcu_data);
struct rcu_node *rnp = rdp->mynode;
if (!(READ_ONCE(rnp->expmask) & rdp->grpmask) ||
__this_cpu_read(rcu_data.cpu_no_qs.b.exp))
return;
if (rcu_is_cpu_rrupt_from_idle()) {
rcu_report_exp_rdp(this_cpu_ptr(&rcu_data));
return;
}
rcu_exp_need_qs();
}
但如果目标 CPU 线程进入了内核态,而且内核关闭了可抢占的功能,那么 synchronize_rcu_expedited 函数只能等待目标 CPU 线程自己切换上下文了。
put_mnt_ns.synchronize_rcu_expedited stuck
现在我们使用的容器一般都会配置 pid_namespace(7) 和 mount_namespace(7) 分别做进程视图隔离以及挂载点隔离。
在新的 pid_namespace PA 里,一旦一号进程退出,一号进程会在 do_exit.exit_notify 里调用 zap_pid_ns_processes 给 PA 下的所有进程发送 SIGKILL 信号,
并主动回收僵尸进程。假设只有这个 PA 下的进程使用了 mount_namespace MA,那么当最后一个线程进入到 do_exit.exit_task_namespaces 阶段时,
它回收 mount_namespace MA 资源。put_mnt_ns.drop_collected_mounts 释放完资源后,它会调用 synchronize_rcu_expedited。
现在遇到的问题是,没有开启抢占模式的情况下,因为某种原因导致某个 CPU 线程卡在 zap_pid_ns_processes.kernel_wait4 阶段。
那么这将导致调用 synchronize_rcu_expedited 的线程也将进入 Disk Sleep 状态。因为内核并不允许并发调用 synchronize_rcu_expedited,其他容器在退出时,那么必定会有线程进入到 exp_funnel_lock 等锁状态。
为了方便复现这个卡顿问题,我们使用 GO 程序来 re-exec 自身来构造出以下进程树。
unshare(CLONE_NEWPID|CLONE_NEWNS) [Start]
|
|
v
rcudeadlock task && rcudeadlock start [Entrypoint]
|
|
v
rcudeadlock start [PID 1 and exit]
|___ rcudeadlock zombie
|__ bash -c "while true; echo zombie; sleep 1; done"
以下使用 Ubuntu v5.15.0-1064-azure 内核复现的日志,可以看到 rcudeadlock start (pid 2928) 进入 kernel_wait4 状态,并长时间霸占 CPU #2 线程上;而它的孩子进程 sleep (pid 3141) 等待在了 synchronize_rcu_expedited。如果后续还有新的进程需要回收 mount_namespace,那么这些进程都将卡在 synchronize_rcu_expedited。
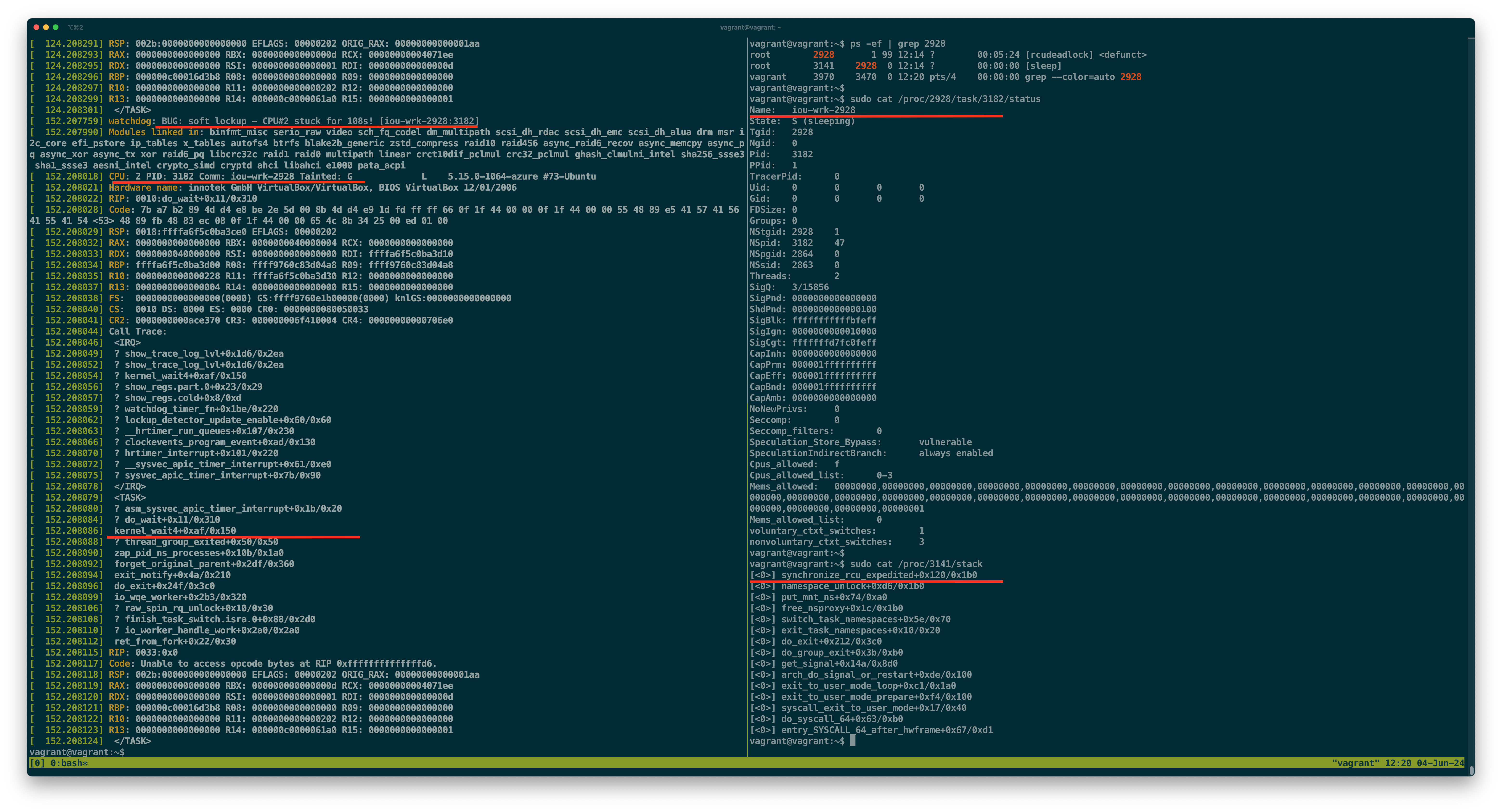
目前还不知道具体原因,但比较有意思的是,一旦在 rcudeadlock 进程中引入 io_uring(7) 空闲线程后,这个问题就特别容易复现。
How to build kernel to reproduce this issue?
编译内核需要关闭 CONFIG_PREEMPT 以及 CONFIG_PREEMPT_RCU,大致如下图所示。
$ cat /boot/config-5.15.0-1064-azure | grep _RCU
CONFIG_TREE_RCU=y
# CONFIG_RCU_EXPERT is not set
CONFIG_TASKS_RCU_GENERIC=y
CONFIG_TASKS_RUDE_RCU=y
CONFIG_TASKS_TRACE_RCU=y
CONFIG_RCU_STALL_COMMON=y
CONFIG_RCU_NEED_SEGCBLIST=y
CONFIG_RCU_NOCB_CPU=y
CONFIG_MMU_GATHER_RCU_TABLE_FREE=y
# CONFIG_RCU_SCALE_TEST is not set
# CONFIG_RCU_TORTURE_TEST is not set
# CONFIG_RCU_REF_SCALE_TEST is not set
CONFIG_RCU_CPU_STALL_TIMEOUT=60
# CONFIG_RCU_TRACE is not set
# CONFIG_RCU_EQS_DEBUG is not set
$ cat /boot/config-5.15.0-1064-azure | grep _PREEMPT
# CONFIG_PREEMPT_NONE is not set
CONFIG_PREEMPT_VOLUNTARY=y
# CONFIG_PREEMPT is not set
CONFIG_HAVE_PREEMPT_DYNAMIC=y
CONFIG_PREEMPT_NOTIFIERS=y
CONFIG_DRM_I915_PREEMPT_TIMEOUT=640
# CONFIG_PREEMPTIRQ_DELAY_TEST is not set
目前在 8 vcores 环境下,运行 rcudeadlock 容易复现。在 v5.15 内核环境下,大概就几分钟的时间就可以复现。而在 >= v6.5 环境下复现时间不固定,有时候需要花几个小时, v6.10-rc2 内核依旧可以复现。