脏页大小 - 18446744073709551614 ?!
April 11, 2024
分享一个 etcd-io/etcd@17615 问题:用户发现 etcd 进程写入 WAL 日志有抖动,但是磁盘压力并不大,而且 fsync 系统调用都很正常; 后来通过 Tracing 工具定位到了内核 memory-cgroup 脏页数据统计有问题,不过该问题仅会出现在 v5.15.0-63 小版本。 17615 问题单里有详尽的定位过程,推荐看看。 因为这个问题,我翻阅了相关的内核 PATCH 邮件,做了以下的脏页分配限流 (简单) 总结。
脏页分配限流 - balance_dirty_pages
回写 (Writeback) 是指内核负责将脏页 (DirtyPage) 刷入存储设备上,它涉及到脏页分配控制。
在 v4.2 版本之前,脏页分配更多是由 memory-cgroup 来控制;而脏页流控核心 - balance_dirty_pages - 根据全局的脏页水位情况来决定是否需要控速。
在 LinuxCon Japan 2015 会议上,内核开发者 Tejun Heo 认为,在没有感知到全局脏页水位的情况,memory-cgroup 无法对脏页进行有效的控制。
核心 balance_dirty_pages 函数通过 vm.dirty[_background]_{ratio, bytes} 参数来计算全局脏页的水位上限。
Tejun Heo 认为普通的 memory-cgroup 也应采用同样的方式来计算组内的脏页水位上限,而根组 memory-cgroup 只不过是退化到全局模式,当然全局脏页的水位优先级更高。
NOTE:
balance_dirty_pages_ratelimited会调用balance_dirty_pages。
在 writeback: cgroup writeback support PATCH 合并到 v4.2 之后,每个 memory-cgroup 都有独立的设备回写控制器 (bdi_writeback),它用于执行回写操作。 回写控制器维护写入带宽 - dirty_ratelimit - ,初始状态下为 100 MiB/s。假设当前脏页大小为 dirty 和同时有 N 个线程在写入,该线程需要等待的时长大约为
pause = dirty / (dirty_ratelimit / N)
在 writeback: dirty rate control PATCH 里,内核开发者 Wu Fengguang 给出了 N = roundup_pow_of_two(1 + HZ / 8) 的计算方法;
自 2011 年以来,内核一直在使用该方法计算 N。
让线程停顿是为了防止脏页增长过快。但如果整体可用内存水位状态良好,内核应该尽量避免不必要的停顿,因此脏页水位有三个状态 freerun, setpoint 和 limit。
threshold = vm.dirty_ratio * total_available_memory
background_threshold = vm.dirty_background_ratio * total_available_memory
* freerun = (threshold + background_threshold) / 2
* limit = threshold
* setpoint = (freerun + limit) / 2
当脏页水位线低于 freerun 时,那么线程并不需要停顿,内存允许脏页快速增长;当脏页水位高于 limit 时,内核将通过 sleep(pause) 来禁止线程写入新的脏页,内核需要通过回写来降低水位线到安全的位置。
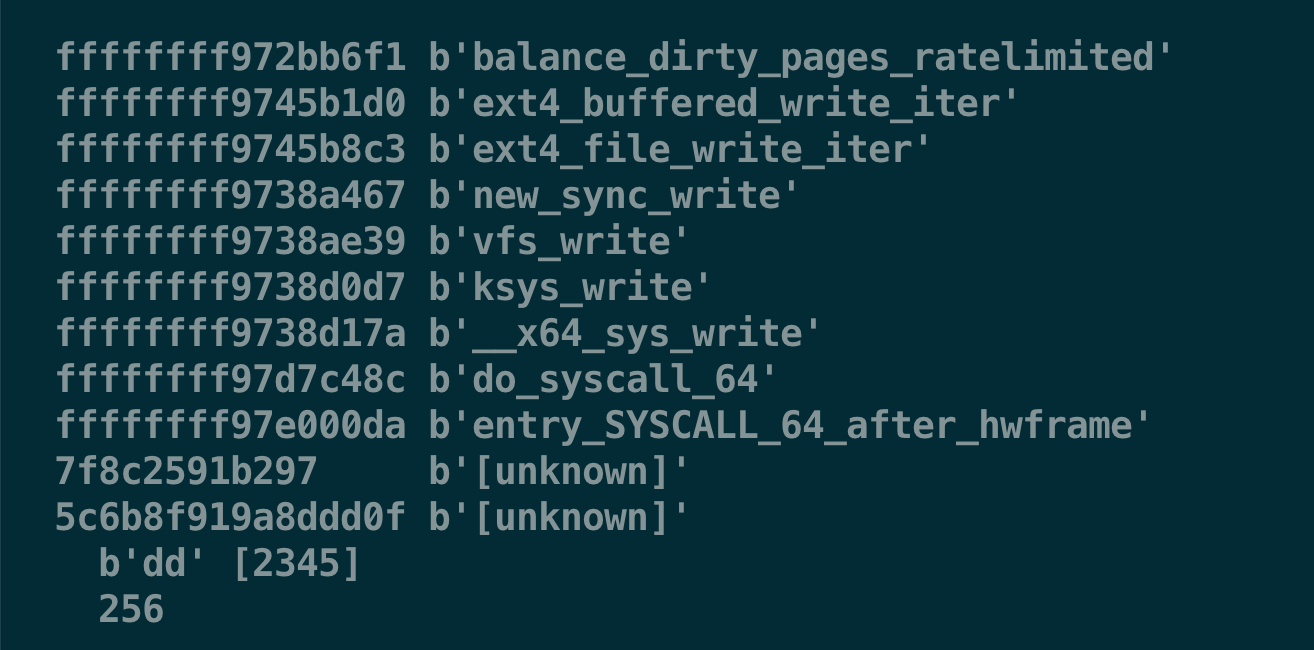
为了更好地计算停顿时长,内核引入了线程级别的带宽概念 task_ratelimit: 利用水位状态 pos_ratio 来调节写入带宽。
* pos_ratio(dirty) = 1.0 + ((setpoint - dirty) / (limit - setpoint) ) ^3
* task_ratelimit(dirty) = dirty_ratelimit * pos_ratio(dirty)
* pause = dirty / (task_ratelimit / N)
内核还会根据 IO 回写控制器的情况来微调 pos_ratio,尤其是在内存较大的机器上能充分利用内存优势,
通过维持较高的写入带宽来迅速降低脏页水位线,细节可以查询 writeback: dirty position control PATCH。
memory-cgroup 脏页状态更新 - rstat
当进程跑在非根组的 memory-cgroup 时,balance_dirty_pages 需要从对应 memory-cgroup 获取当前的脏页大小。
2019 年 mm: memcontrol: make cgroup stats and events query API explicitly local PATCH 让内核在更新侧 (内存的分配和释放) 做 per-cpu 的批量数据聚合,减少读取侧因遍历 memory-cgroup 树形结构测带来的 CPU 消耗。 假设每次更新 32 个页的数据,在 32 CPU 下运行着 32 个 memory-cgroup,那么最大误差会在 128 MiB 左右。 为了解决误差和读取效率问题,内核开发者 Johannes Weiner 在 mm: memcontrol: switch to rstat PATCH 里引入了 rstat 框架: 更新侧仅需为祖辈们维护 pending-update cgroup 队列,而读取侧仅选择性地做数据聚合,减少了不必要的遍历。
假设当前 memory-cgroup 结构为 root -> A -> B -> C,当线程在 C 内分配了内存,那么内核在更新 C 的同时,它也会标记 B, A, root 为待更新状态;
当有线程需要读取 C 状态时,那么读取侧需要将 B, A, root 也更新了,才能保证 root -> A -> B -> C 链路上的数据是一致的。
如果新增了 root -> A -> D -> E memory cgroup, 但 D, E 没有数据的变化,那么在读取 C 的数据时,内核并不会遍历 D, E。
rstat 架构的选择性聚合优化了读取效率和准确性。关于 rstat 的更多细节可以查看 Linux Plumbers Conferences 2022 - cgroup rstat’s advanced adoption。
脏页大小 - 18446744073709551614 ?
回到 ETCD 遇到的这个问题上。
在更新 memory-cgroup 字段时,线程仅更新当前 CPU 的 memcg->vm_stats_percpu->state 上,由读取侧调用 cgroup_rstat_flush_locked 函数来做 CPU 级别的数据聚合。
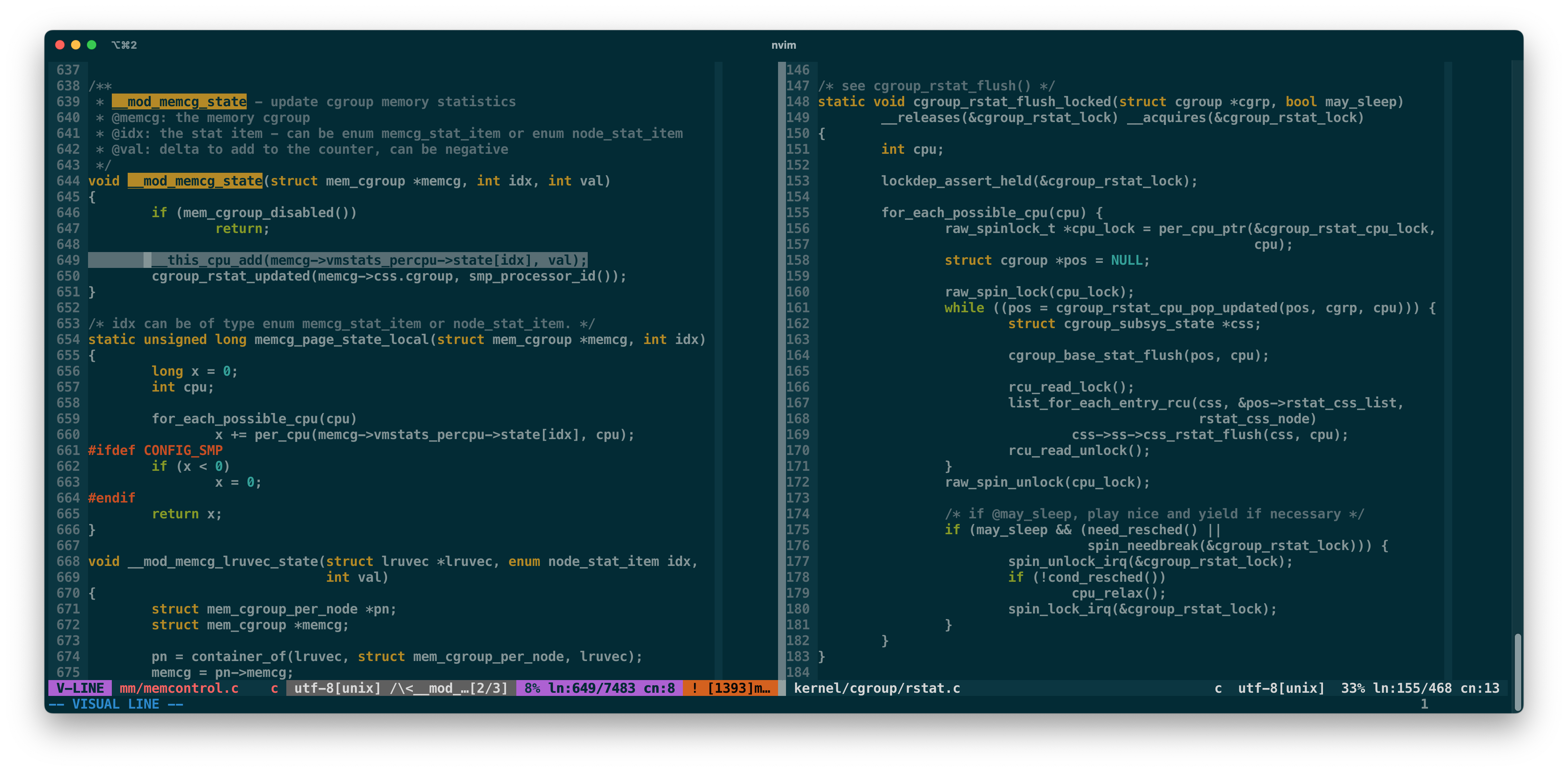
那么问题来了,假设有 32 个 CPU,当 cgroup_rstat_flush_locked 读取第三个 CPU 上的数据时,第一个 CPU 产生了新的脏页,然后被第 30 个 CPU 刷盘了。
错过了第一个 CPU 产生的增量,导致在那个时刻的统计结果里脏页是负数。虽然状态最终是正确的,但负数被转化成 unsigned long 将变成非常大。
static inline unsigned long memcg_page_state(struct mem_cgroup *memcg, int idx)
{
return READ_ONCE(memcg->vmstats.state[idx]);
}
根据前面提到的停顿时长计算公式,线程相当于无限期停服了。 好在内核允许的最大停顿时间为 200 ms,下一轮检查大概率就恢复正常了。 Revert “memcg: cleanup racy sum avoidance code PATCH 修复也非常简单,就是回滚之前的一个 PATCH。
我在一个 CPU 32 vcores - Memory 64 GiB 虚拟机上复现了这个问题:
* 单实例 ETCD 运行在 /sys/fs/cgroup/testing1 里,并使用 ETCD benchmark 疯狂发写请求
* 反复在 /sys/fs/cgroup/testing2 里运行 dd 来产生大量的脏页,迫使 ETCD 进程进入 balance_dirty_pages
通过 Tracing Event 日志发现,脏页大小为 18446744073709551614 (-2)。
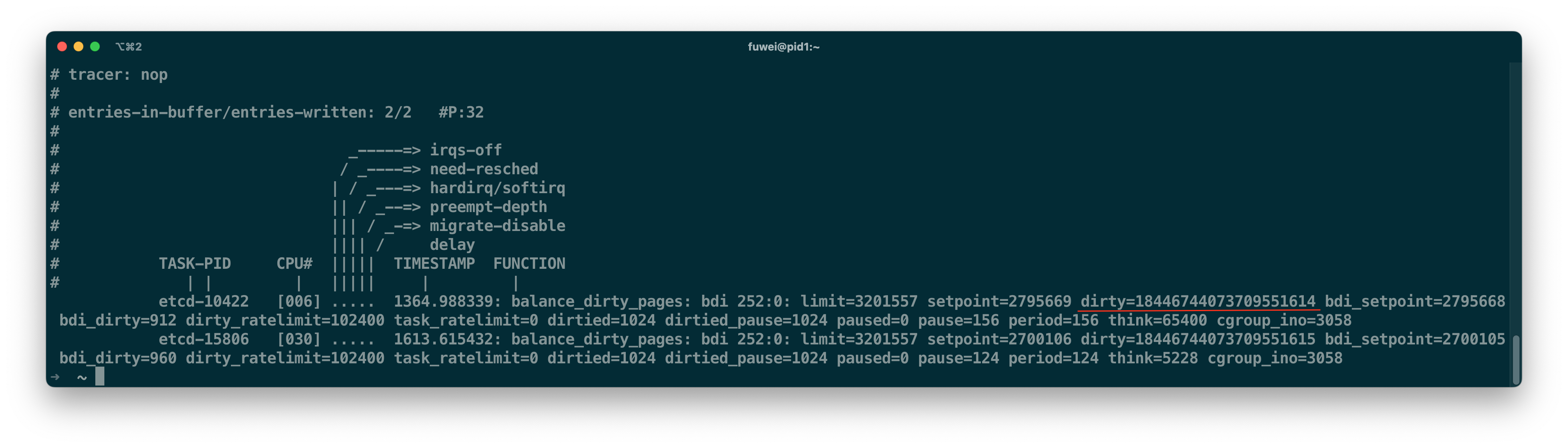
核数越多,越容易遇到这个问题。
最后
博客停更好久了,有时间就多写写吧。