containerd 1.7: UserNamespace Stateless Pod
March 4, 2023
containerd 1.7 版本有比较多的实验特性。在这里,我会介绍 containerd 对 UserNamespace Stateless Pod 支持的情况,算是个人对 containerd 1.7 版本特性介绍系列的开篇。
1. UserNamespace 安全特性
Linux 内核是基于进程的 credentials(7) 凭证来做访问控制,比如进程的拥有者标识 UID/GID 和用于系统资源访问控制判定的 Effective UID/GID 等凭证。而 user_namespace(7) 提供了安全隔离特性。在不同的 user namespace(userns) 下,同一个进程不仅有不同的 UID/GID,同时还具备了不同的 capabilities(7) 权限。比如 u1001 用户进程 bash 通过 unshare -r bash 进入到了新的 userns,并将自己映射成了 root 用户,还具备了所有的 capabilities。但这个进程真的就变成了特权进程?这取决于该用户在系统资源所属的 userns 里是否拥有访问权限。
在介绍具体的判定规则前,先花点时间了解下内核是如何管理 UID/GID 的映射关系。
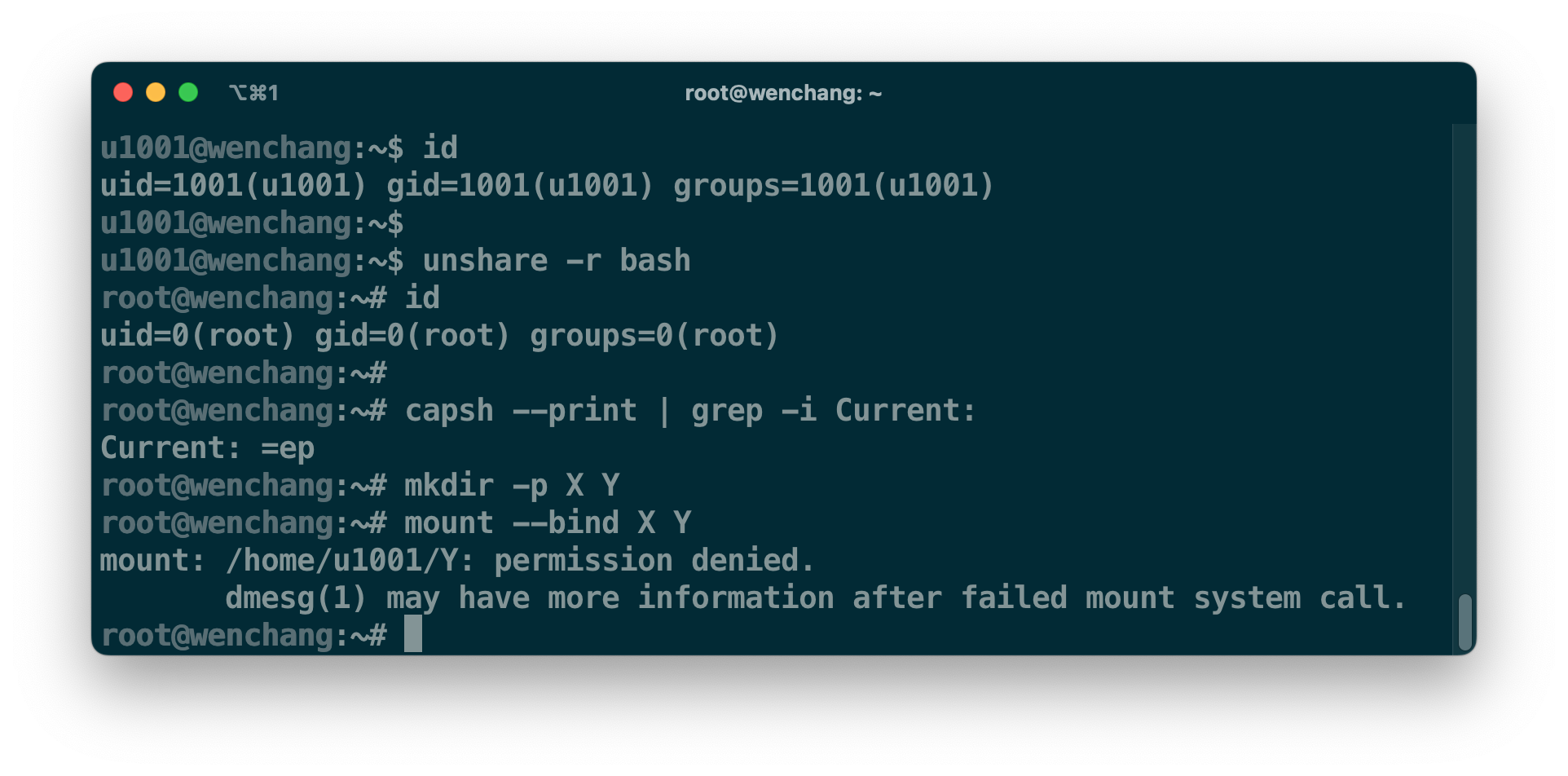
每个进程都必须归属于某一个 userns。在初始状态下,进程都属于 initial userns。Initial userns 比较特殊,它没有任何映射关系;Linux 支持嵌套的 userns,所有正在使用的 userns 组成的关系图将会是以 initial userns 为根的树状图。在 parent userns 里的进程,只要具备 CAP_SET{UID,GID} 能力,这些进程就可以通过 /proc/[pid]/{uid,gid}_map 文件接口,以 ID-inside-ns ID-outside-ns Range-length 的格式,给刚进入 child userns 的进程设置 UID/GID 映射关系,而创建该 userns 进程的 Effective UID(EUID) 将成为 userns 的所有者,如下图所示。

在上图中,有两层 userns 映射关系:
uid_map: 0 1001 10将 initial userns 的 UID[1001, 1010]映射到 userns X 里的 UID[0, 9]uid_map: 10 0 5将 userns X 中的 UID[0, 4]映射成 userns Y 里的 UID[10, 14]。
但这些都是用户态的映射关系,uid_map 文件接口会将其转化成 内核态的映射关系 userspace-id:kernel-id:range(u:k:r),比如 u1000:k0:r100 映射关系可以把 k10 映射成 u1010 = k10 - k0 + u1000;同样的,u1005 可以转化为 k5 = u1005 - u1000 + k0,其中 r100 是用来判断映射是否超出范围。Initial userns 的 ID 映射关系是 u0:k0:r4294967295,相当于 u 等于 k。Userns X 的 parent userns 是 initial userns,结合 uid_map 的配置,内核态的映射关系应为 u0:k1001:r10;同理 Userns Y 的内核态映射关系是 u10:k1001:r5。在进行权限判断时,内核最终都以 kernel-id 为凭据。
回到最初的话题,为什么具备了所有 capabilities 还是不能进行 bind-mount?
Linux 的系统资源都归属于某一个 userns,比如 mount_namespace(7) 下的挂载资源,network_namespace(7) 下的设备资源等等。当进程想要访问系统资源时,内核会采用下面的策略来决定进程是否有权 (为了方便解释,被访问的系统资源属于 userns X,而访问该系统资源的进程属于 userns Y):
- 在 initial userns 为根的树状关系里,当 userns X 是 userns Y 的祖先或者是兄弟分支,进程无权访问;
- 当 userns X 与 userns Y 相等或者 userns Y 是 userns X 的祖先时,只要进程具备资源要求的 capabilities 即可访问;
- 当 userns Y 是 userns X 的父节点,且当前进程的 EUID 为 userns X 的创建者,那么该进程可以访问 userns Y 下的所有系统资源。
判断进程的 EUID 是否为 userns X 的所有者时,内核比较的是 kernel-id。上诉的判断来自 cap_capable 函数。大部分的权限判断都包着它来做,比如挂载权限的判断逻辑在 may_mount 等,感兴趣的可以去看看。
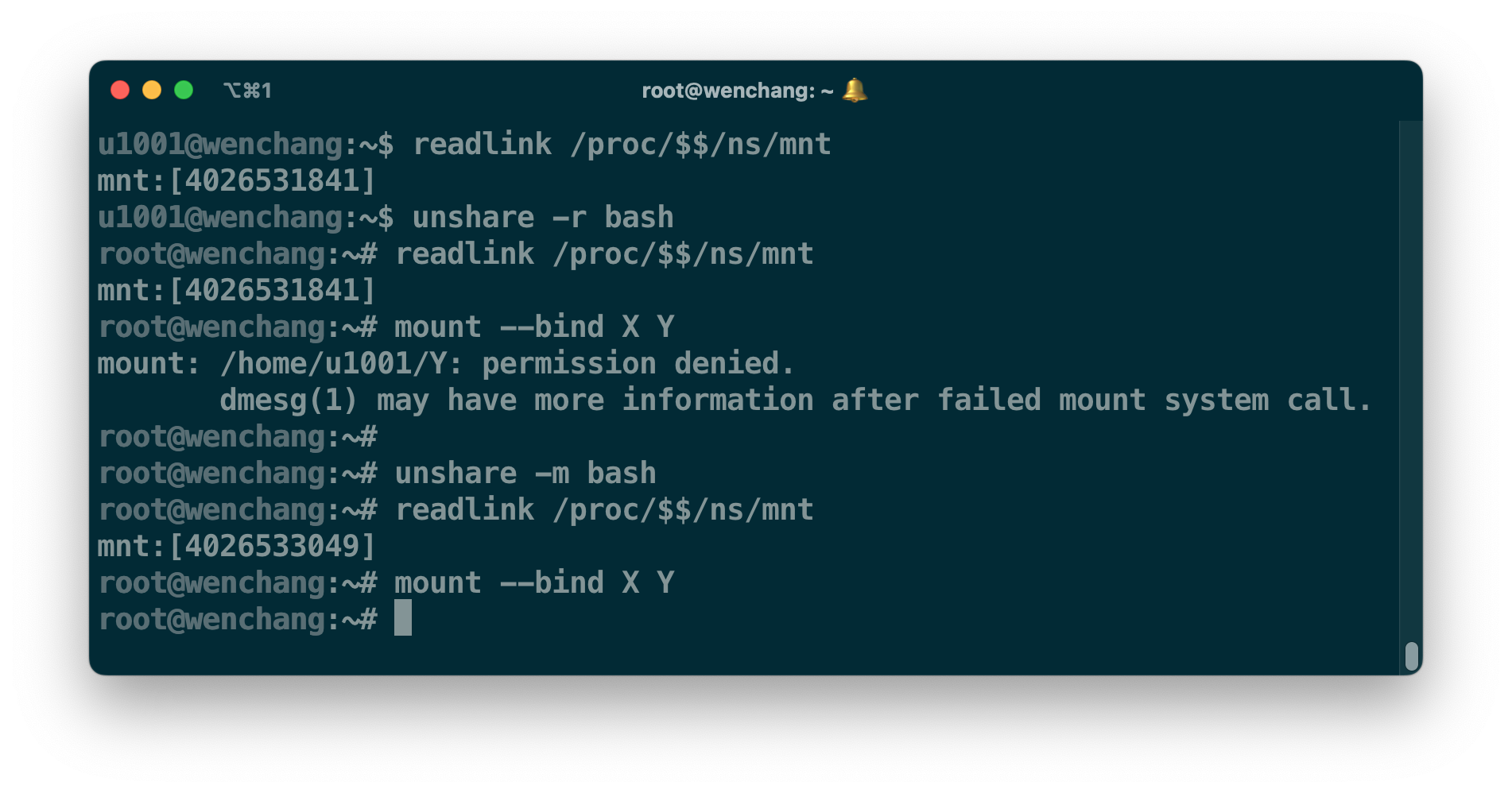
如上图所示,虽然 unshare 切换了 userns,但 mount_namespace(mountns) 依然属于 parent userns。根据访问策略来看,当前进程无权访问祖先 userns 的资源,因此挂载失败。如果想要在不提权的情况下进行挂载,最好的方式就是 unshare 切换新的 mountns。全新的 mountns 将属于当前的 userns;当前进程具有 SYS_ADMIN 权限,所以它能进行挂载。
现在的容器默认会配置独立的 mount/network/pid/ipc/uts_namespace(7) 资源,没有的独立的 userns,这些系统资源依旧隶属于 initial userns。而大部分容器进程都以 root 用户身份启动,为了防止容器进程逃逸后对系统造成破坏,业界的普遍做法是限制容器进程的 capabilities,同时采用 SELinux/Apparmor 安全规则控制对系统资源的访问。但这毕竟都是后验形式,集群管理员需要对容器进程做大量的行为审计,他们才能得到有效的安全规则。但就目前的结果来看,现在依然有不少 initial userns 的权限泄漏所引发的安全问题。
既然全新的 userns 可以完全禁止进程访问隶属于 initial userns 的系统资源,那么为什么迟迟不落地呢?
2. FSUID 映射问题
在 Linux 系统里,一个进程有两个关键的身份凭证:一个是前面提到的 EUID,它用于做系统资源的权限判断;而另外一个是 Filesystem UID(FSUID),它用来判断是否有权限访问文件目录。一般情况下只要不调用 setfsuid,进程的 FSUID 都和 EUID 保持一致。
当进程在创建文件目录时,文件系统会将当前进程 FSUID 的映射结果写入到存储设备。当然,文件系统并不是持久化当前 userns 的映射结果。当进程挂载文件系统时,内核会将该进程所在的 userns caller u:k:r 映射关系作为对应文件系统的 fs u:k:r 映射关系。文件系统会将创建文件进程的 FSUID kernel-id 转化成 fs u:k:r 下的 userspace-id,这个 id 才是最终存储的结果。有了这个概念后,我们看下查看文件拥有者标识的过程。
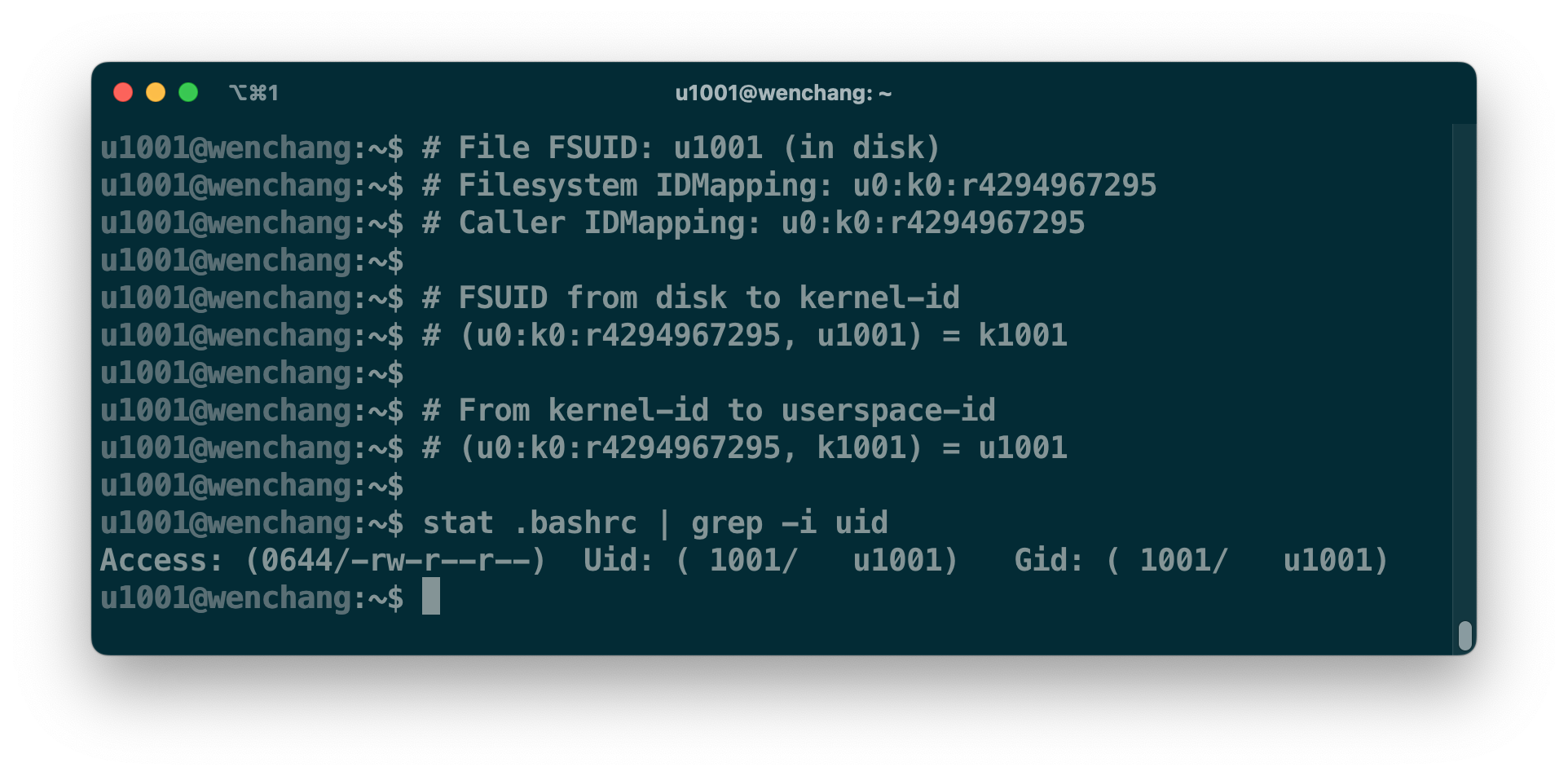
假设用户 u1001 HOME 目录所在的文件系统采用了 fs u0:k0:r4294967295 映射,以及当前 stat 进程的 userns 也采用了同样的映射 caller u0:k0:r4294967295。文件系统先将存储设备里的 u1001 转化成 k1001,内核再通过当前进程的映射关系转化,最终得到我们所看到的 u1001。
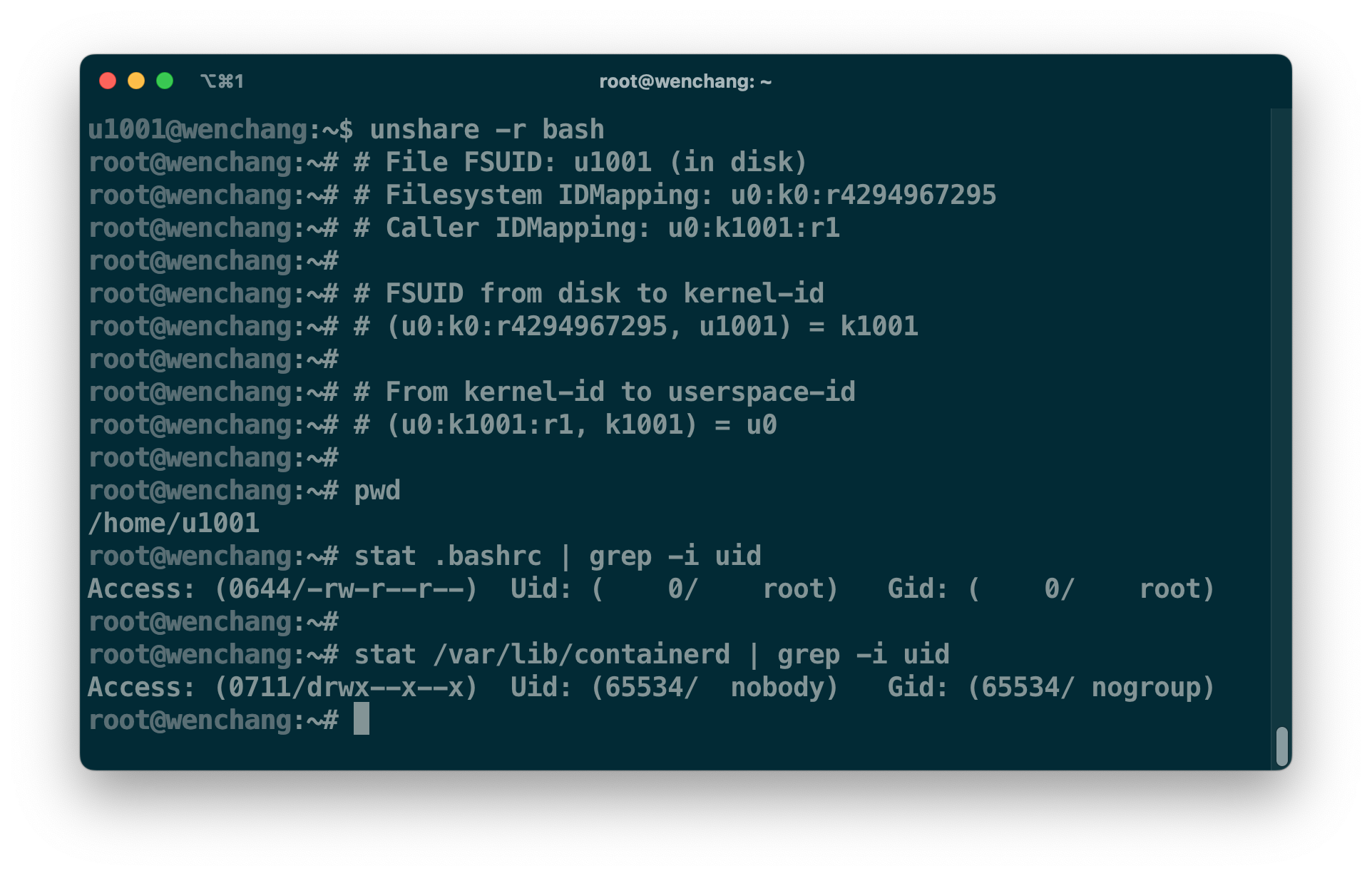
让我们再看看把 u1001 映射成 root 用户后的显示效果,如下图所示。因为进程已经切换到了新的 userns,但 .bashrc 文件的存储没有发生变化,经过两次映射,我们最终看到的是 u0。原先 /var/lib/containerd 在存储设备里的 FSUID 是 u0,经过 fs u0:k0:r4294967295 映射后得到 k0,但 k0 并不在 caller u0:k1001:r1 的范围内。对于这些不在映射范围内的 UID,内核统一显示成 nobody(65534)。这也意味着,当前 root 用户依然无法访问 /var/lib/containerd。
回到容器的使用场景。首先,绝大多数的容器镜像是以 root 用户构建,这就要求容器进程的 FSUID 经过映射后要和存储对应的 FSUID 一致。为了方便解释,这里假设容器镜像的底层文件系统采用 initial userns 映射方式。如果容器进程采用 caller r0:k1001:r1 映射,那么它是无权访问镜像内容,它将无法启动。解决这个问题的方式,就是在启动容器前,我们通过 chown -R 把容器的根录都修改成 u1001。但这也意味着效率低下。
| Image | Size | Inodes | overlayfs w/ metacopy | overlayfs w/o metacopy |
|---|---|---|---|---|
| tensorflow/tensorflow:latest | 1489MiB | 32596 | 1.29s | 54.80s |
| library/node:latest | 1425MiB | 33385 | 1.18s | 52.86s |
| library/ubuntu:22.04 | 83.4MiB | 3517 | 0.15s | 5.32s |
当我们在修改容器根目录的文件属性时,如果没有 metacopy=on 的属性支持,那么 chown -R 在修改文件属性前,overlayfs 文件系统会将这个文件从只读层拷贝到可写层。如果文件越大,整个修改过程就越慢,同时还产生磁盘压力;带上 metacopy=on 之后,至少 overlayfs 仅拷贝文件的 metadata,效率高不少。但面对小文件特别多的场景,chown -R 操作依旧很耗时。与此同时, chown 还是永久性修改文件属性。
然而不同容器之间可能会共享同一个数据卷。常见的场景有:容器 A 以 caller r0:k1001:r1 映射关系产生数据,然后容器 B 再进行分析消费。这就要求容器 B 也必须使用 r0:k1001:r1 映射关系,否则只能再次使用 chown 来切换。
在全民白嫖镜像仓库的形势下,镜像仓库已经变成 免费数据 仓库。个人见过上百 GiB 的容器镜像,在这种容器镜像面前使用 chown,这简直是劝退。
3. Mount idmapped 特性 >= kernel v5.12
为了解决这个映射的难题,Linux v5.12 版本 引入了挂载点的映射关系 mount u:k:r,用户可以通过它来绕过文件系统原先的 fs u:k:r 映射,其中该特性由 mount_setattr(2) 系统调用提供。我们直接看例子解释吧,如下图所示。
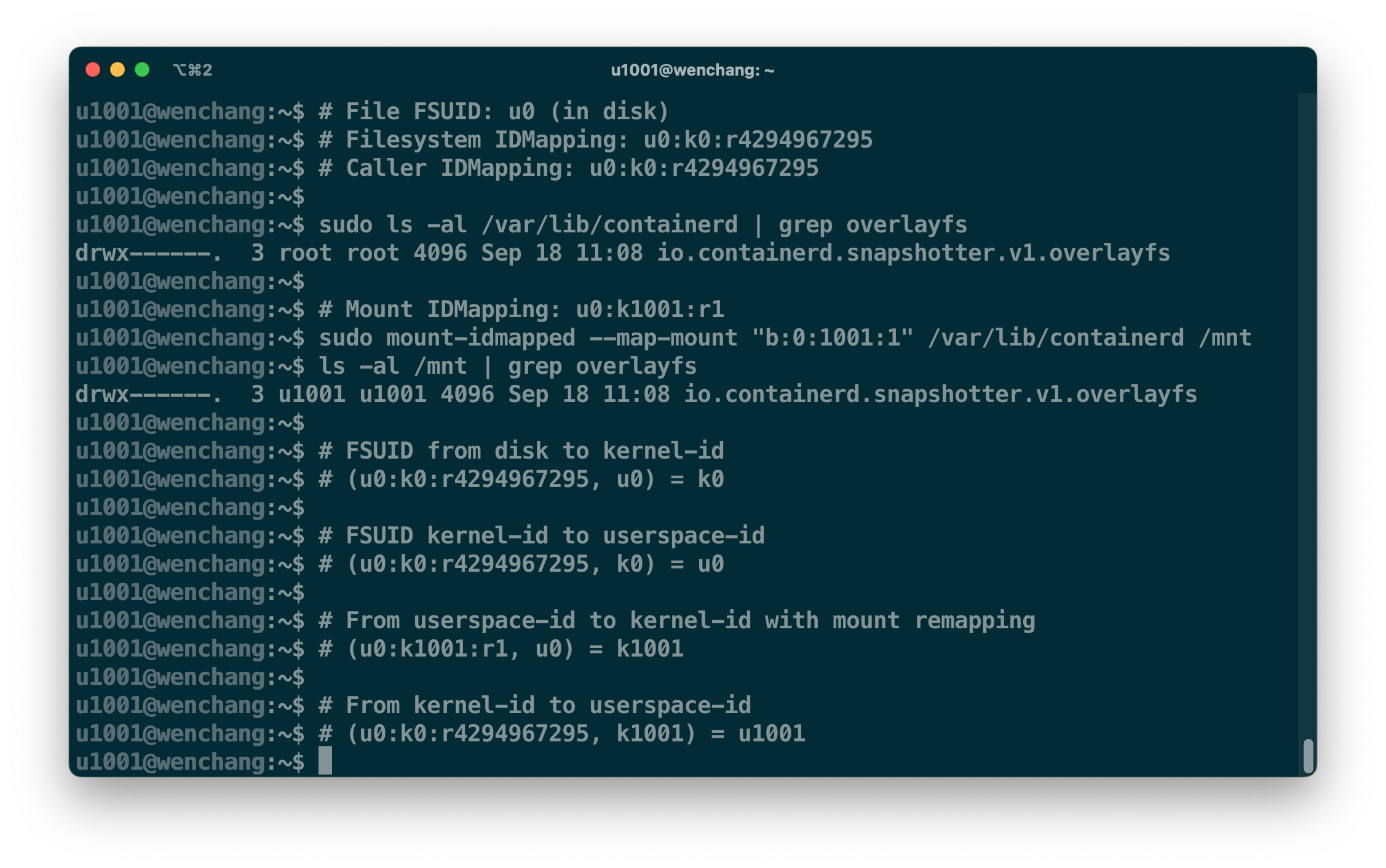
mount-idmapped 工具把 /var/lib/containerd 挂载到 /mnt 下,并通过 mount u0:k1001:r1 映射关系将其 授权 给 u1001 用户进程访问,u1001 用户无需提权就可以在 /mnt 下访问 /var/lib/containerd 的数据。挂载点 /mnt 上的 mount u0:k1001:r1 映射关系是替代了原先的 fs u0:k0:r4294967295。只是底层文件系统 inode 保存的是 fs u:k:r 映射后的 kernel-id;而 mount u:k:r 由 Virtual filesystem(vfs) 模块管理,vfs 拿不到存储设备上保存的 userspace-id,所以 vfs 需要利用 fs u:k:r 转化回来。这也就是上图里,u0 -> k0 -> u0 转化看似无效,但它其实是真实的处理流程。
如果 u1001 用户进程在 /mnt 目录里进行写操作,通过上图的映射关系,新文件的 FSUID 最终将以 u0 落盘。
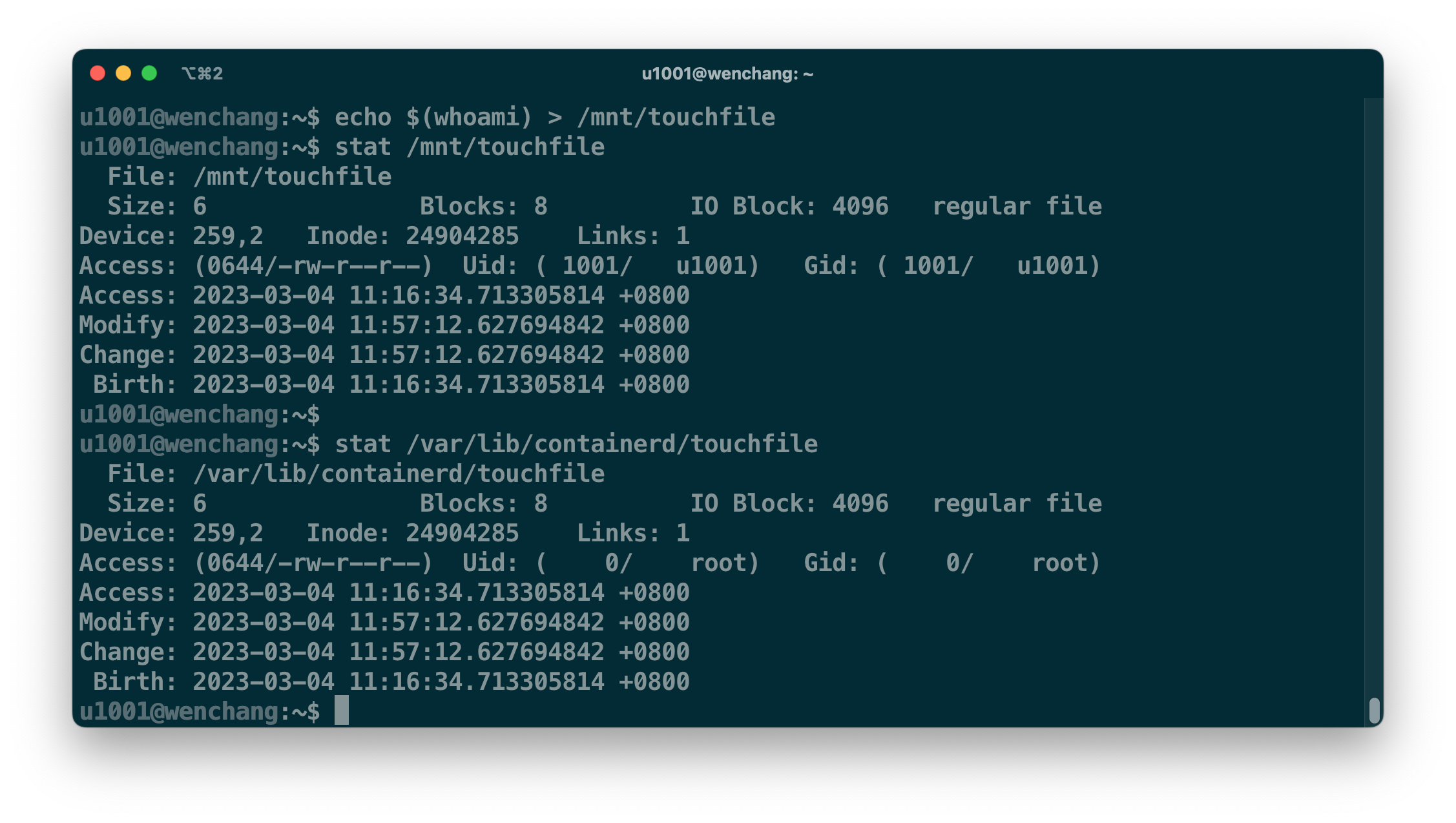
无论多大的文件目录,该内核特性都可以很快完成 FSUID 映射,还可以同时支持多个 mount u:k:r 映射,也解决了数据卷共享问题。我想这就是为什么社区开始推进 userns 落地的原因吧。
4. containerd 目前的集成情况
为了支持 userns,containerd 对 CRI RunPodSandbox 的流程有比较大的改动,但这仅针对 userns 场景的 Pod,其他场景和之前保持一致。
4.1 依旧使用 chown 修改容器根目录
containerd 并没有使用 mount_setattr 特性,目前还是使用 chown 的形式。为了减少不必要的 chown 操作,containerd 将首次 chown 之后的容器根目录做成只读 snapshot,而对于后续使用相同镜像以及相同 uid_map 的容器而言,containerd 可以直接用现成的 snapshot 做根目录。也算是一个优化吧。
没有集成 mount idmapped 的主要原因在于,它对 containerd 现有的 mount 挂载流程影响比较大。
Linux v5.19 overlayfs 文件系统开始支持 mount idmapped,但它是针对只读层设计,用户无法对一个已挂载好的 overlayfs 文件系统进行 mount idmapped,毕竟 overlayfs 并没有像 ext4/xfs/btrfs 那样拥有 FS_ALLOW_IDMAP。
// https://elixir.bootlin.com/linux/v6.1.15/source/fs/namespace.c#L3979
static int can_idmap_mount(const struct mount_kattr *kattr, struct mount *mnt)
{
...
/* The underlying filesystem doesn't support idmapped mounts yet. */
if (!(m->mnt_sb->s_type->fs_flags & FS_ALLOW_IDMAP))
return -EINVAL;
...
}
为此,我们需要将容器镜像的只读层挨个进行 mount idmapped,最后再挂载成 overlayfs。或者是将容器镜像直接解压到已经 mount idmapped 好的挂载点上。但后者对现有 containerd snapshot 管理有比较大的冲击,前者看起来会更容易落地些。
值得一提的是,新版本内核已经演进出了新的 mount API: fsopen(2)/fsconfig(2)/fsmount(2) 将文件系统挂载拆成多次系统调用,而且 fsmount(2) 仅是生成 anonymous mount 记录,需要 move_mount(2) 将其转化成可见的挂载点。而普通的 bind mount 将由 open_tree(2) 来产生 anonymouns mount。
mount_setattr 有一个要求就是必须是 anonymouns mount。但除了 fsopen,fsconfig/fsmount/open_tree 都没进入 golang.org/x/sys/unix。整体来看,mount_setattr 在 containerd 上落下来可能还需要几个月的时间。
4.2 延后网络初始化
早期 dockerd 的容器网络初始化是在 runC 进入 init 阶段后,runC 通过 prestart_hook 回调通知 dockerd, dockerd 再通过 setns(2) 进入到容器 network namespace(netns) 进行配置。
同样,kubelet 在处理 dockershim 的网络时,它也是等待 pause 容器启动后,并通过 /proc/[pause-pid]/ns/net 来进行 CNI 调用。但这里有一个很大的问题就是,一旦 pause 容器进程被意外杀死,同时原先 pause 容器进程 pid 被复用,那么 CNI 将会在错误的 netns 里进行操作。运气不好的话,CNI 可能会操作到 initial userns 下的 netns,造成整机的网络中断。
而 containerd CRI 当前的设计可以避免 pid 复用所引发的问题。在启动 pause 容器前,containerd 会提前准备好 netns,并将其持久化到 /run/netns 之下。这个行为和 ip netns add 行为一致,如下图所示。CNI 初始化完毕后,containerd 才将持久化后的 netns 地址交给 runC。这完全避免了 pid 复用的问题。
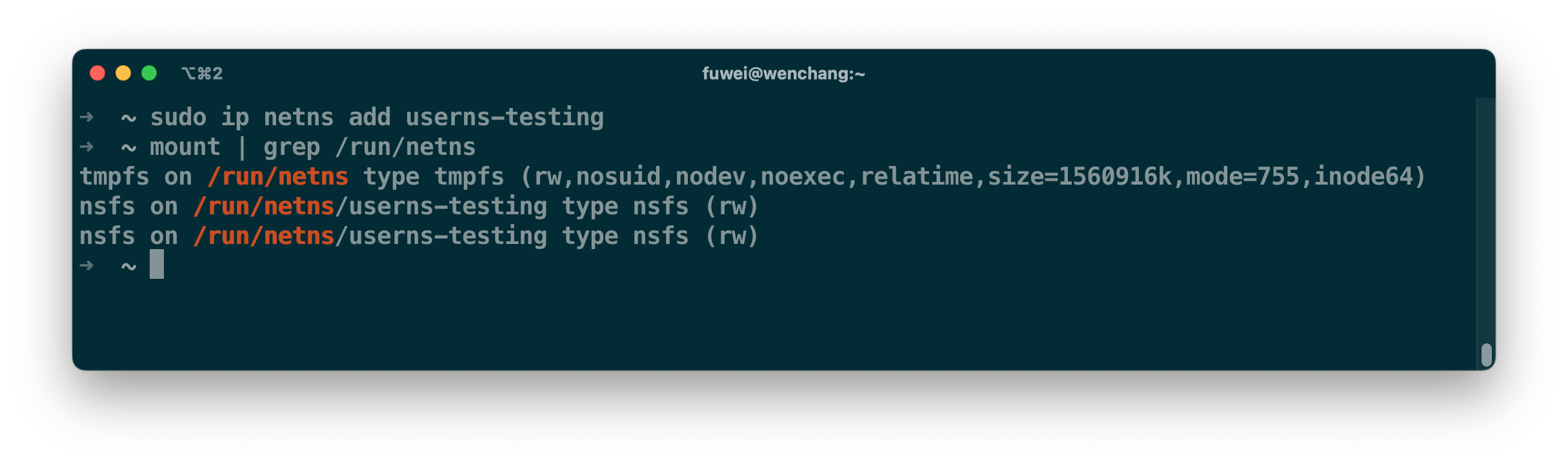
但这个不适用于 userns 场景,因为 containerd 创建的出来 netns 属于 initial userns,而且它还挂载在属于 initial userns 的 mountns 里。新的 userns 无法操作 netns 下的资源,同时因为 netns 归属问题,还导致 runC 无法将 /sys/ 挂载容器根目录。
解决这个问题的唯一途径就是让 runC 创建 netns。为了防止出现 pid 复用问题,在 runC init 阶段结束后,containerd 将 /proc/[pause-pid]/ns/net 持久化到 /run/netns 之下,然后再判断 runC init 进程是否还处于运行状态,避免出现 datarace 的情况。
为了避免对现有容器运行时集成的影响,这个处理逻辑仅针对使用 userns 的容器,原先支持的场景不受影响。
5. 最后
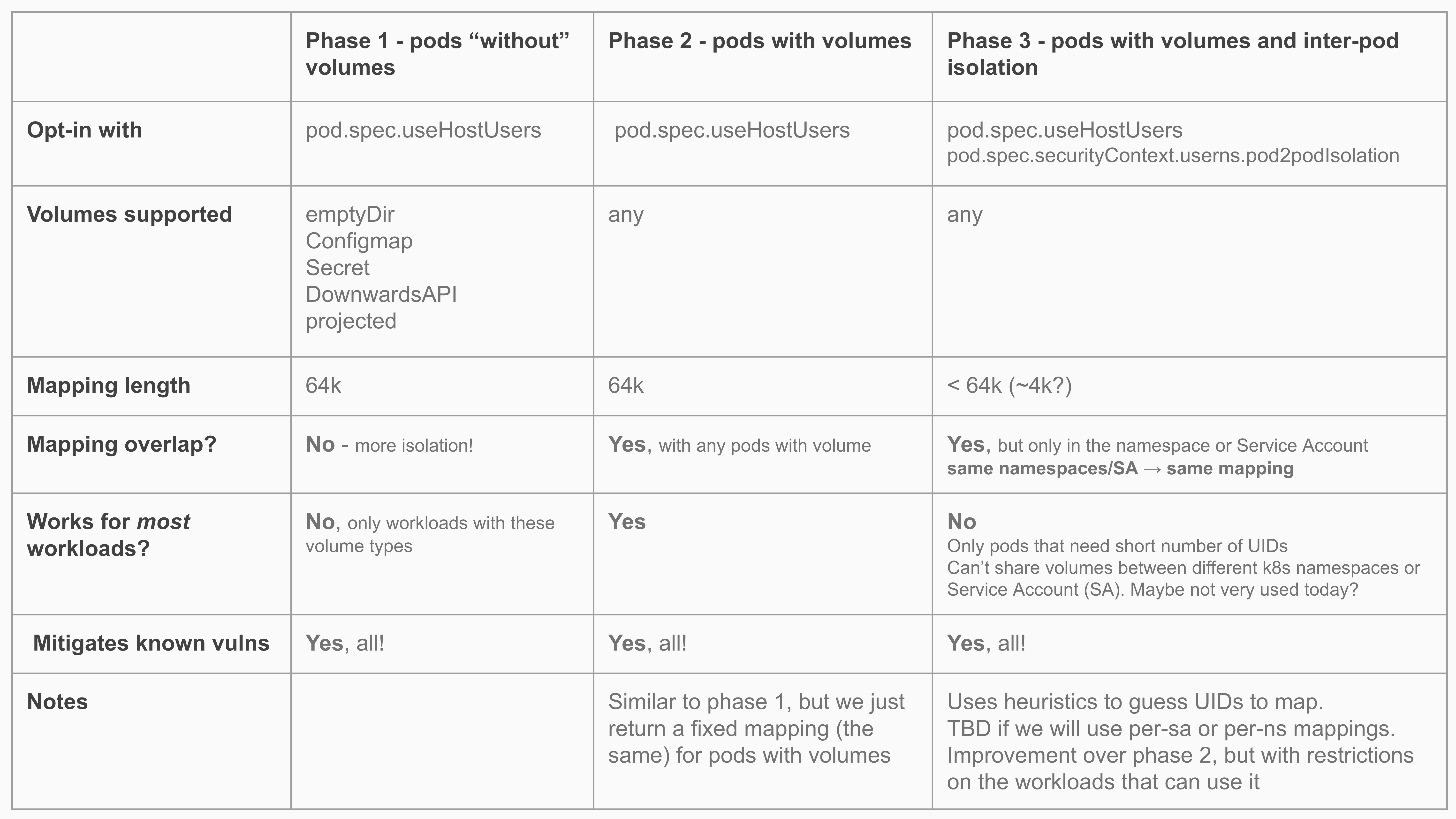
目前该特性距离上生产还有很长的路要走,下图是 Kubernetes SIG-Node 之前讨论过规划。除此之外,还得看用户侧是否实时跟进新内核,以及各大 Linux 发行版商是否会及时 backport 新版本特性。
个人倒是很喜欢这个特性,因为 userns 几乎可以让容器进程更好地享受隔离特性,减少 seccomp 这些作用不大但影响性能的配置干扰。说到这,我想起前同事做过的镜像构建项目,因为安全问题,管理员迟迟不愿意开放 mount 挂载权限。如果这个特性能推广,应该能减少很多不必要的会了吧。。。