containerd 1.7: 垃圾回收的拓展
March 19, 2023
之前和苦总/Ace 维护 pouch-container/containerd 的时候,我们遇到比较多的问题是资源泄漏,比如节点负载太高以至于无法 umount 容器根目录(容器 bundle 目录残留),内核 pidns 死锁问题导致容器进程僵尸态( cgroup 残留),还有进程重启导致 CNI 网络资源泄漏等等。对于内核死锁等问题,重启可能是唯一的解决方案;而那些因为短期高负载或者进程重启导致的资源泄漏,它们需要从系统层面解决,至少应该让资源的创建者有机会去清理。
containerd 它本身就具备垃圾回收能力,但它只关注内部资源的清理,比如镜像数据以及容器可写层。而 CNI 网络资源以及 containerd-shim 等外部资源并不在垃圾回收的管理范围内,这部分资源容易出现泄漏的情况,比如 GKE 平台的用户就多次遇到了 Containerd IP leakage : 直到 pause 容器创建之前,containerd 仅在内存里保持对网络资源的引用;在将网络资源绑定给 pod 以前,containerd 一旦被强制重启就会发生泄漏。当时 containerd 社区的处理方式是提前创建 pod 记录,以此来提前关联网络资源,并利用 kubelet 的垃圾回收机制来触发资源清理。问题倒是解决了,但该方案仅适用于 kubernetes 场景,最合理的方案应该是创建者应具备周期性的清理流程。
考虑我们还有 shim 资源泄漏的问题,containerd 社区提了 Add collectible resources to metadata gc 方案来管理外部资源清理。在介绍这个方案之前,我想先介绍下 containerd 的垃圾清理机制。
基于标签系统和 lease 构建的垃圾回收
containerd 核心插件 metadata 管理着容器和镜像数据,如下图所示,其中虚线方块代表着子模块,比如 Images 代表着 image service,它仅用来管理镜像名字和镜像 manifest 的映射关系,而镜像的 blob 数据和解压后的文件内容分别由 content service 和 snapshot service 管理;需要说明的是,container service 仅用来保存用于启动容器的配置信息,它并不负责管理容器进程的生命周期。
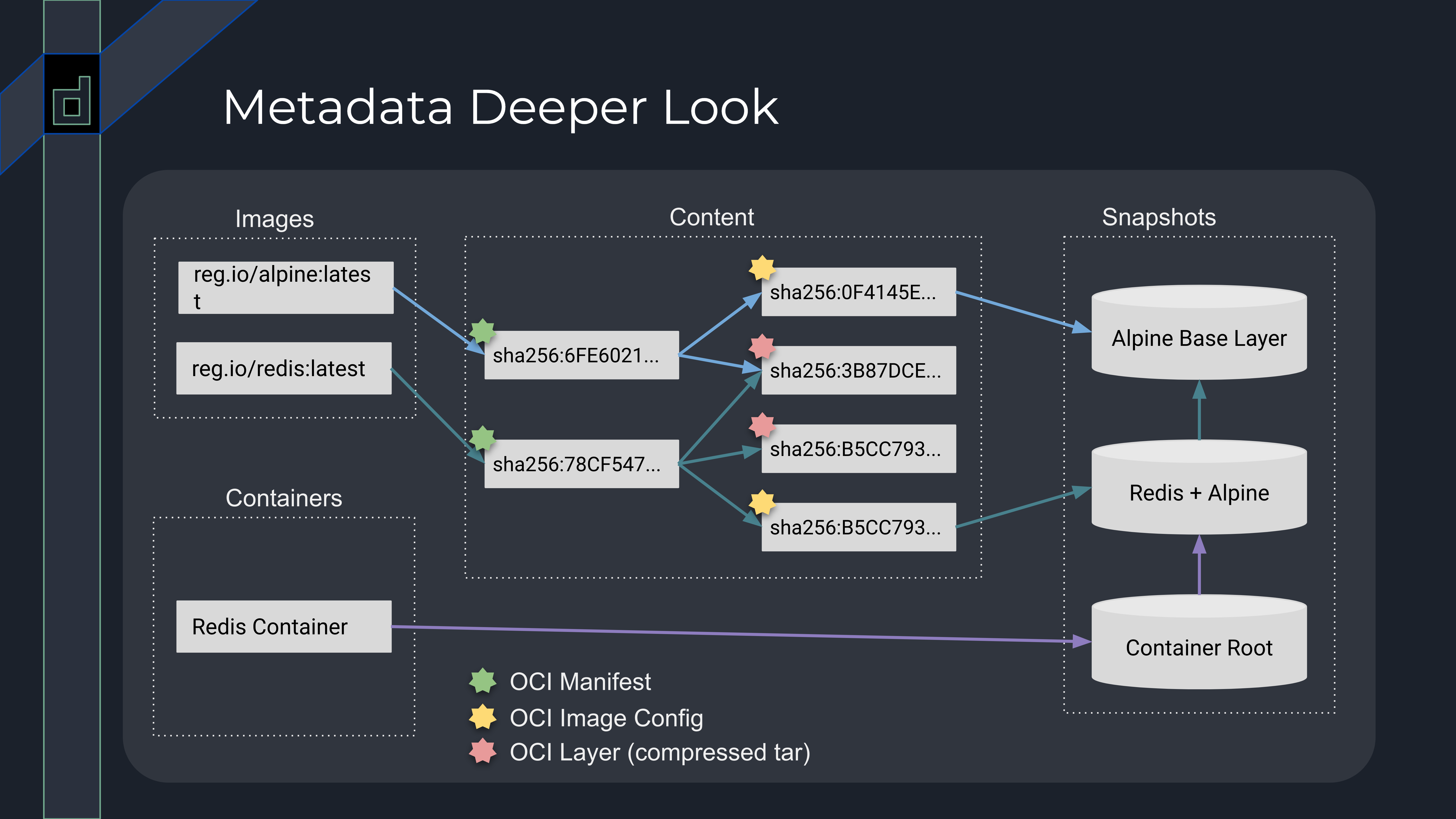
上图的方向键代表着数据之间的关联性,但除了 image/container 可以直接指向其相关联的数据外,content 数据间的关系以及 content 和 snapshot 数据间的关系都将通过标签系统来维系。
根据 OCI 镜像标准的定义,镜像 manifest 的数据内容会关联其配置信息 config 以及 layer 的数据。在 containerd content service 里,这些数据的关系将由标签 containerd.io/gc.ref.content. 来呈现,如下图的所示。
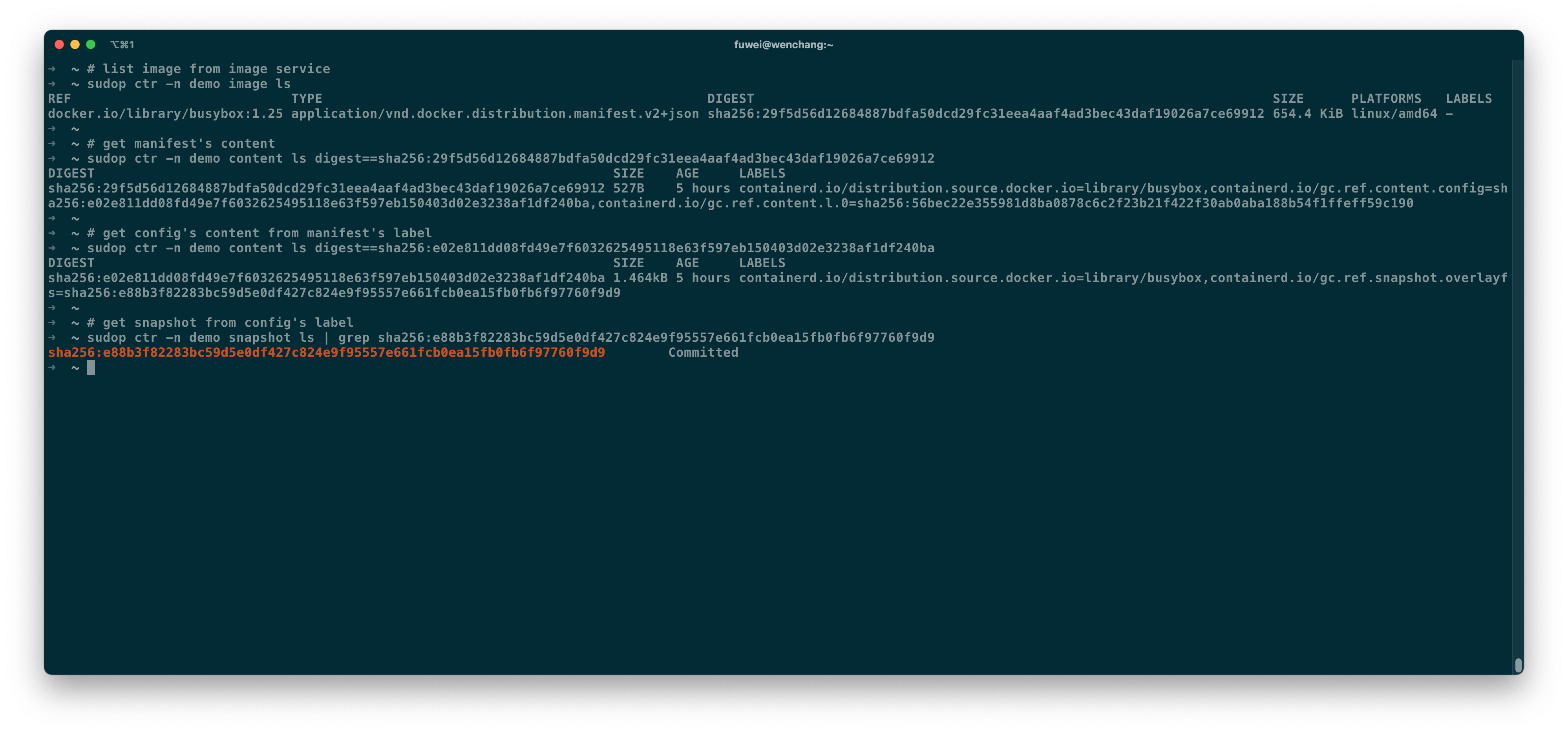
busybox:1.25 镜像名字关联着一个哈希值为 sha256:29f5d56d1… 的 manifest,而这个 manifest 身上有两个重要的标签,如下表所示,它们分别指向了 config 和 layer 哈希值。由于每一层 layer 数据都对应着一个 snapshot,而这些 snapshot ID 是来自 config 里的 diffID 所生成的 chainID。为了管理方便,containerd 在 config 上添加标签 containerd.io/gc.ref.snapshot.X 来关联最后一层 snapshot,其中 X 表示具体的 snapshotter 插件,比如 linux 平台常用的 overlayfs。
| Key | Value | Ref |
|---|---|---|
| containerd.io/gc.ref.content.config | sha256:e02e811dd… | config |
| containerd.io/gc.ref.content.l.0 | sha256:56bec22e3… | layer |
containerd.io/gc.ref.content.l.N 用来指向具体的镜像层,N 代表的是第几层。
现在我们回头看第一张图,container/image 的元数据就可以作为垃圾回收的 GC-Root,containerd 配合标签系统进行全局扫描,并通过 Tricolor 来获得正在使用的数据,那些没有被关联到的数据就可以被删除。
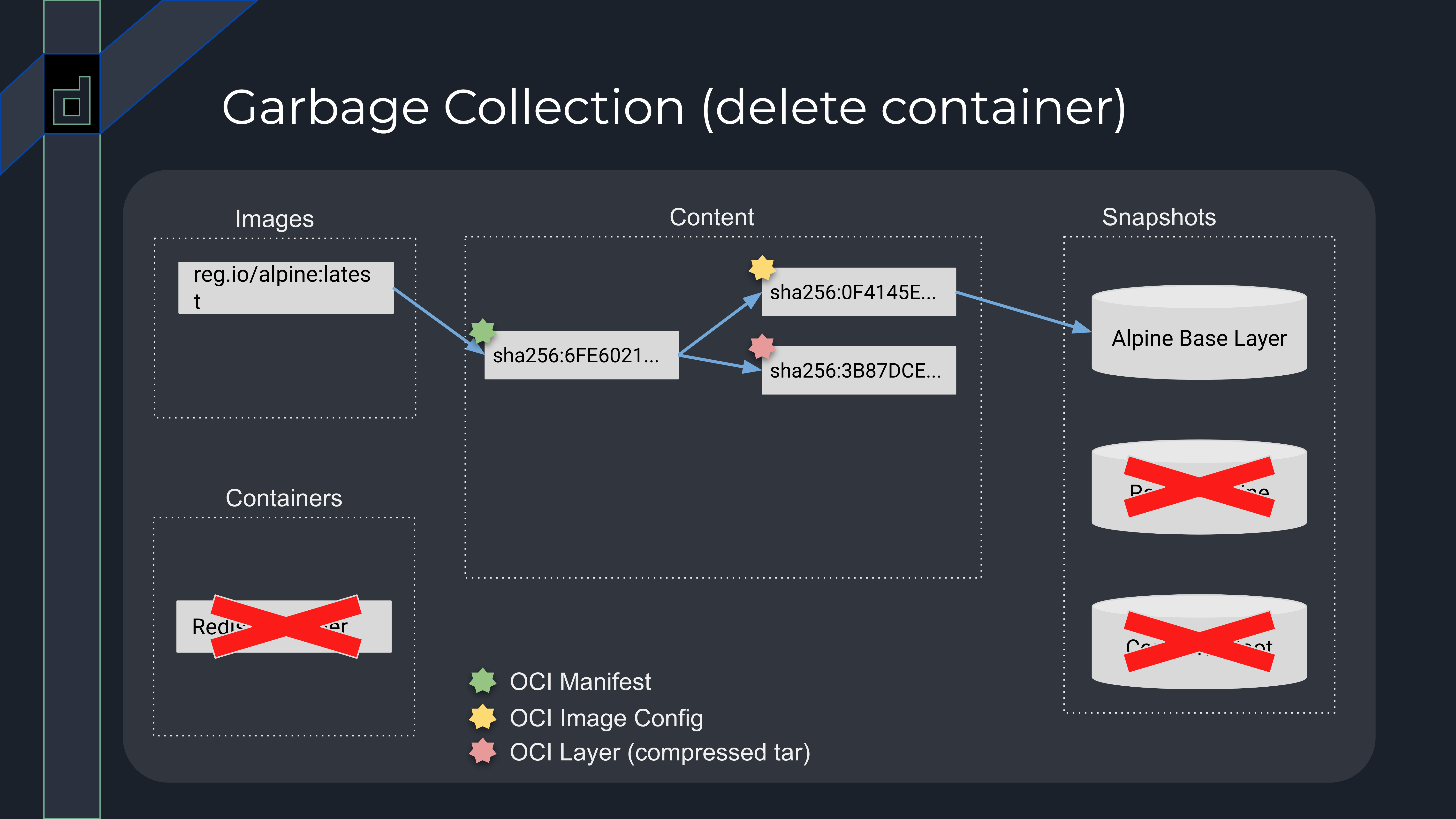
比如我们将 redis:latest 镜像删除之后,redis:latest 镜像关联的 manifest sha256:78CF547… 没有可达的路径;同样地,redis:latest 镜像的 config sha256:B5CC793… 也没有可达路径。但图中的 redis:latest 镜像是基于 alpine:latest 构建,所以 redis:latest 镜像的第一层 sha256:3B87DCE… 将被保留;加上 Redis container 容器关联的可写层 Contaner Root 是基于 redis:latest 构建,因此垃圾回收仅会清理没有可达路径的 content 数据。
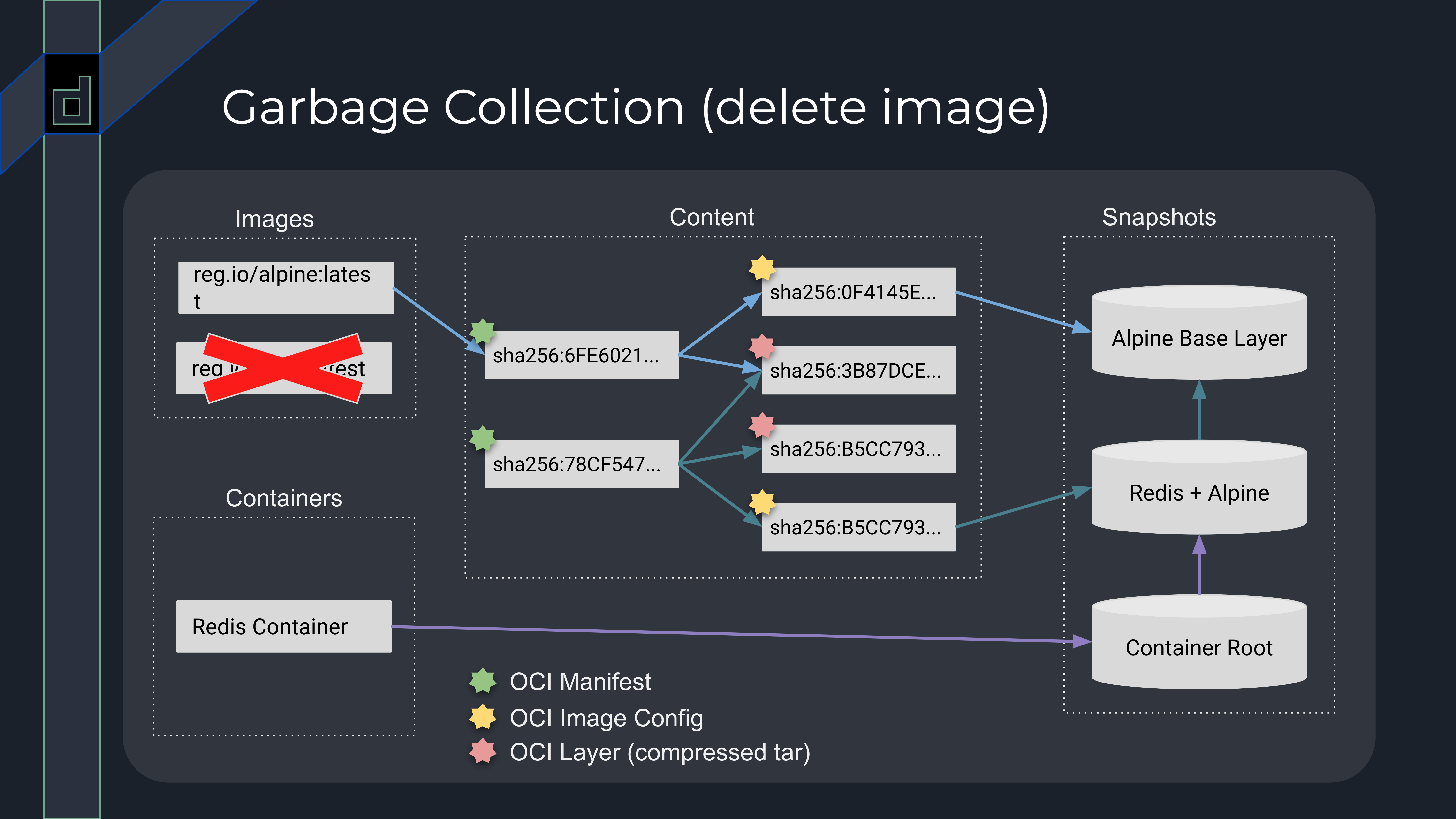
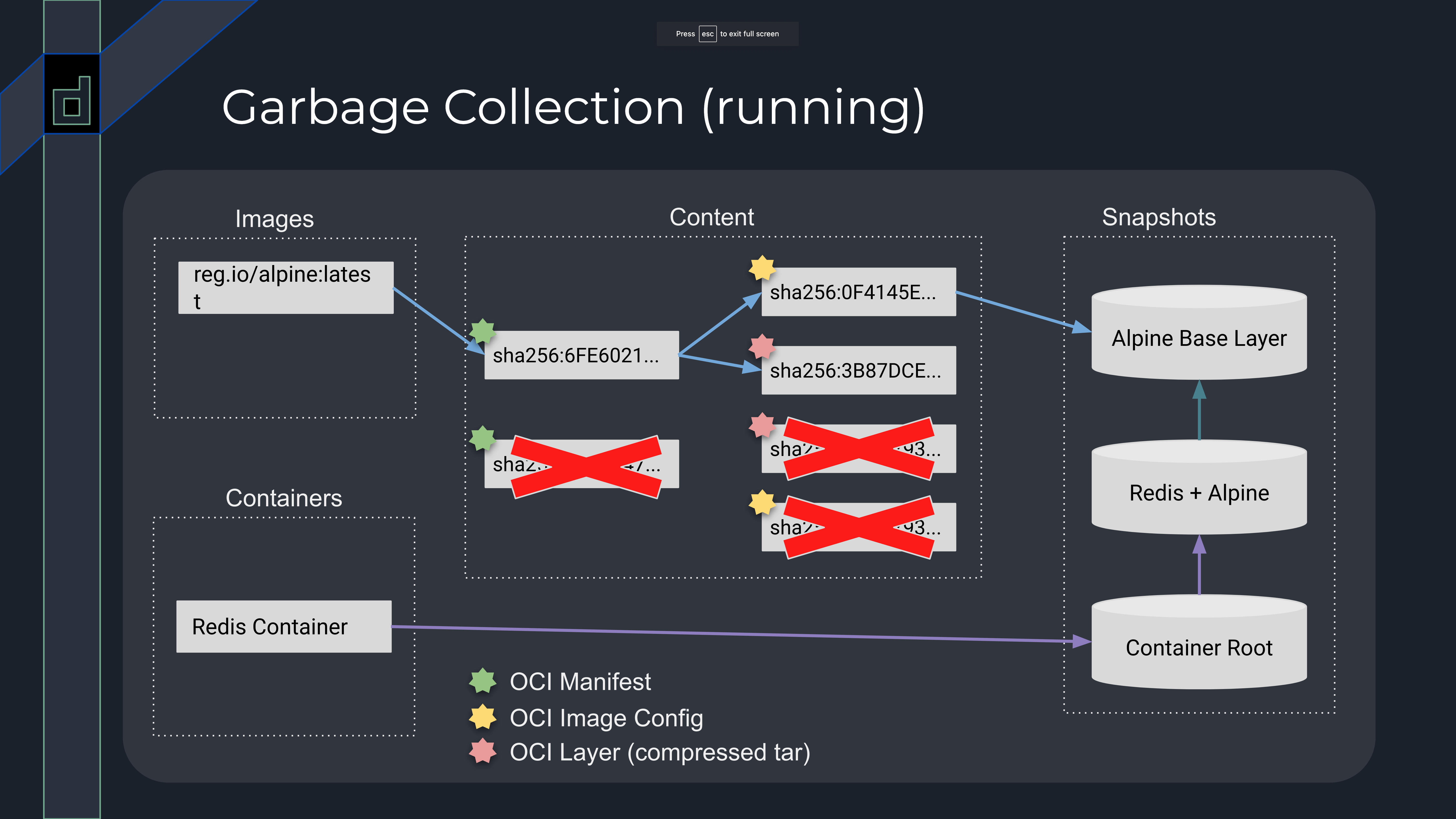
如果在此基础上删除 Redis container,那么 Redis + Alpine 和 Container Root snapshot 将没有可达路径,它们也将会被垃圾回收清理。在这里也侧面解释了 为什么 containerd 允许用户删除正在被容器使用的镜像: 垃圾回收并不会真正去清理容器根目录所依赖的 snapshot,只有等到没有容器或者镜像引用时,containerd 才会真正去删除镜像相关的数据。
前面提到了标签系统如何关联数据,那么你可能会问,containerd 垃圾回收流程会清理正在下载的镜像数据吗?毕竟调用 image service 关联 mainifest 是下载流程的最后步骤。如果没有 lease 关联,containerd 会清理正在下载的镜像数据。
下载镜像是一个不可控的事务,它的耗时由镜像大小、网络带宽以及磁盘读写能力来决定。为了避免未关联的临时数据被删除,containerd 引入了 lease 数据作为新的 GC-Root。它和 image/container 数据平级,它所关联的 content/snapshot 不会被垃圾回收清理。因此下镜像的第一步就是去申请 lease。
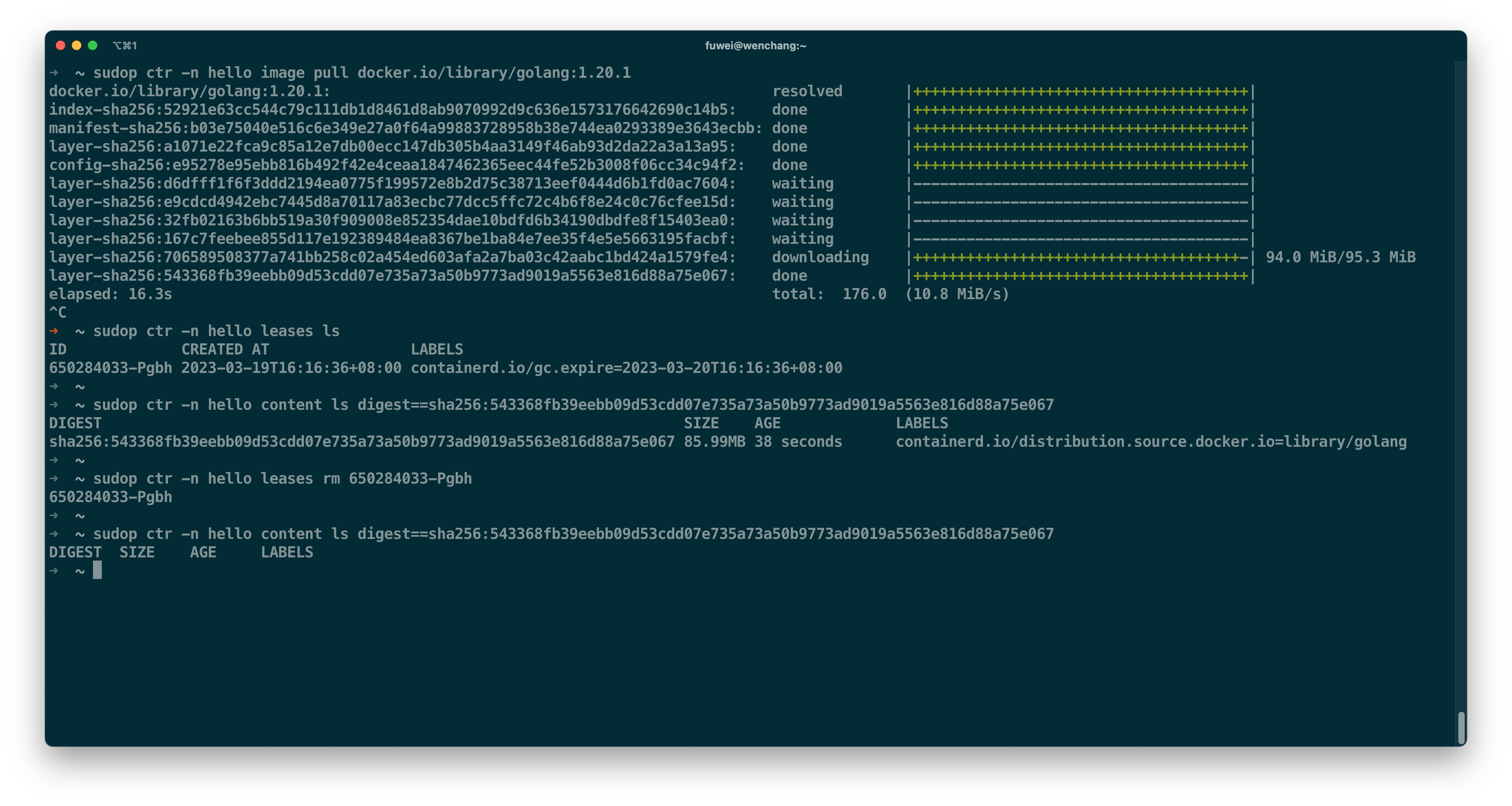
如上图所示,我中途取消了 golang:1.20.1 镜像的下载,其中一个 layer sha256:543368fb… 没有被清理掉,因为它已经被 lease 650284033-Pgbh 关联上了。一般情况下,lease 数据上都会有标签 containerd.io/gc.expire 来表明过期时间。过期之后,lease 和它关联的数据都会被 containerd 清理。如果我没有删除 lease,而是选择重新下载 golang:1.20.1 镜像,containerd 可以恢复取消前的状态,它具备 断点续传 的能力。
新版本的拓展能力
前面提到的垃圾回收仅针对容器和镜像数据,并没有涉及其他资源。但标签系统足以将 metadata 定义的 GC-Root 资源关联到外部组件定义的资源信息,现在仅需要 containerd 提供垃圾回收的标记机会即可。 为此, containerd 社区为 metadata 插件引入了 GC Collector 插件接口,如下图所示。
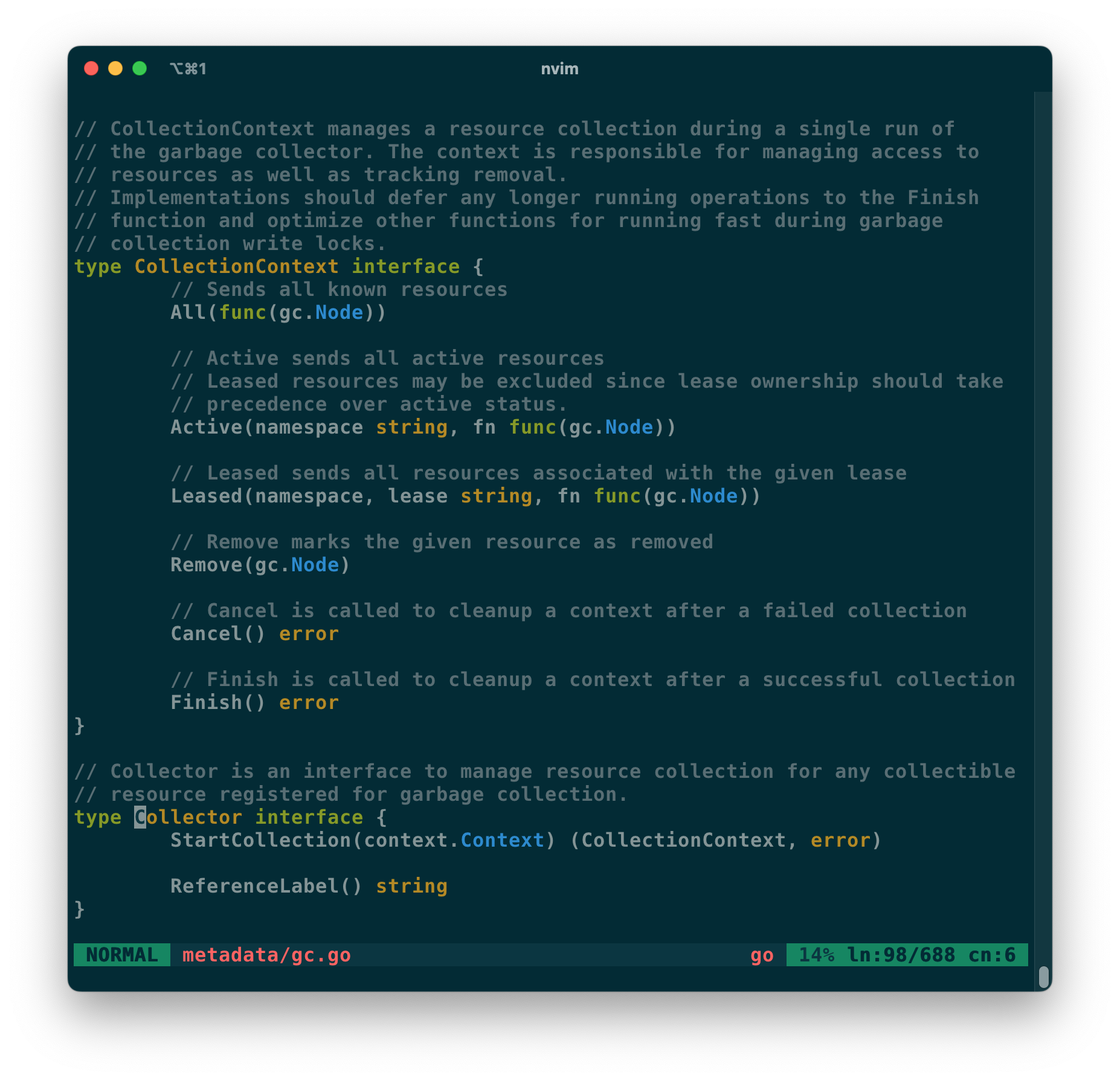
在标记 GC-Root 阶段,containerd 给予 GC Collector 三种方式标记:
-
第一种是在扫描 lease 资源的阶段。在扫描某一个 namespace 下的 lease 时,containerd 将通过 CollectionContext.Leased() 方法来告知插件: 请把当前 namespace 下所有跟这个 lease 有关的数据都通过 fn 回传回来。目前 streaming service 主要采用这种方式标记。
-
第二种是扫描 container/image 数据标签的阶段。Collector.ReferenceLabel() 告知了 containerd 它感兴趣的标签,这个标签以 containerd.io/gc.ref. 开头。比如 CNICollector 插件用来管理容器的网络资源,它维护容器和 netns 路径间的关联关系。当 container 数据创建时,它的 netns 路径为 /run/netns/demo,那么开发者可以为 container 数据添加一条标签 containerd.io/gc.ref.cni=/run/netns/demo。当 containerd 在扫描 container 数据时,它会将 /run/netns/demo 作为可达对象。
-
第三种是扫描完某一个 namespace 的路径发起点之后,containerd 会调用 CollectionContext.Active() 来告知插件:请把当前 namespace 下所有正在使用的数据通过 fn 回传回来。
当 containerd 标记完所有 GC-Root 后,它会扫描所有数据,并删除没有被关联到的数据;之后它将调用 CollectionContext.All() 来遍历插件维护的所有数据,并调用 CollectionContext.Remove() 来清理没被关联上的数据;最后调用 CollectionContext.Finish() 来结束本次清理。
有了这个拓展包之后,理论上所有和容器相关的资源都可以被监控起来,比如开头提到的 CNI 网络资源、containerd-shim 进程,甚至是 containerd-shim 创建出来的 socket 文件。
但需要明确的是,这个拓展包针对的是 containerd 开发者,并不是终端用户。
containerd v2.0 计划
目前比较明确的是,由 AWS 开发者主导的 [Proposal] Add Networks Service Plugin 会重新改变现有 CRI 的网络管理方式。而像 shim process leaked when the host having high disk i/o usage 这些泄漏问题,可能会涉及到 Sandbox API 的改造,进展应该不会太快吧。
最后
这次没有展开解释 containerd 如何清理 snapshotter 数据,个人觉得这部分设计还是不错的,感兴趣的开发者可以去看看这部分实现。这次就到这吧,下一篇会是 containerd 1.7 特性系列介绍的最后一篇。